Luku 1 Korrelaatio ja regressio
1.1 Korrelaatiokerroin
Pearsonin korrelaatiokerroin mittaa kahden tilastomuuttujan välistä lineaarista riippuvuutta. On muunlaisia riippuvuuden tyyppejä, joista se ei kerro.
Esim. R-ohjelmistoon sisältyvä aineisto anscombe sisältää neljä muuttujaparia \(x\) ja \(y\). Kussakin tapauksessa muuttujien välinen riippuvuus on erilainen, mutta korrelaatiokerroin on sama.
attach(anscombe) # Aineiston muuttujat liitetään R:n hakupolkuun.
op <- par(mfrow = c(2, 2)) # Piirretään kuviot 2*2-taulukkoon
plot(x1, y1, xlim = c(3, 20), ylim = c(3, 15))
plot(x2, y2, xlim = c(3, 20), ylim = c(3, 15))
plot(x3, y3, xlim = c(3, 20), ylim = c(3, 15))
plot(x4, y4, xlim = c(3, 20), ylim = c(3, 15))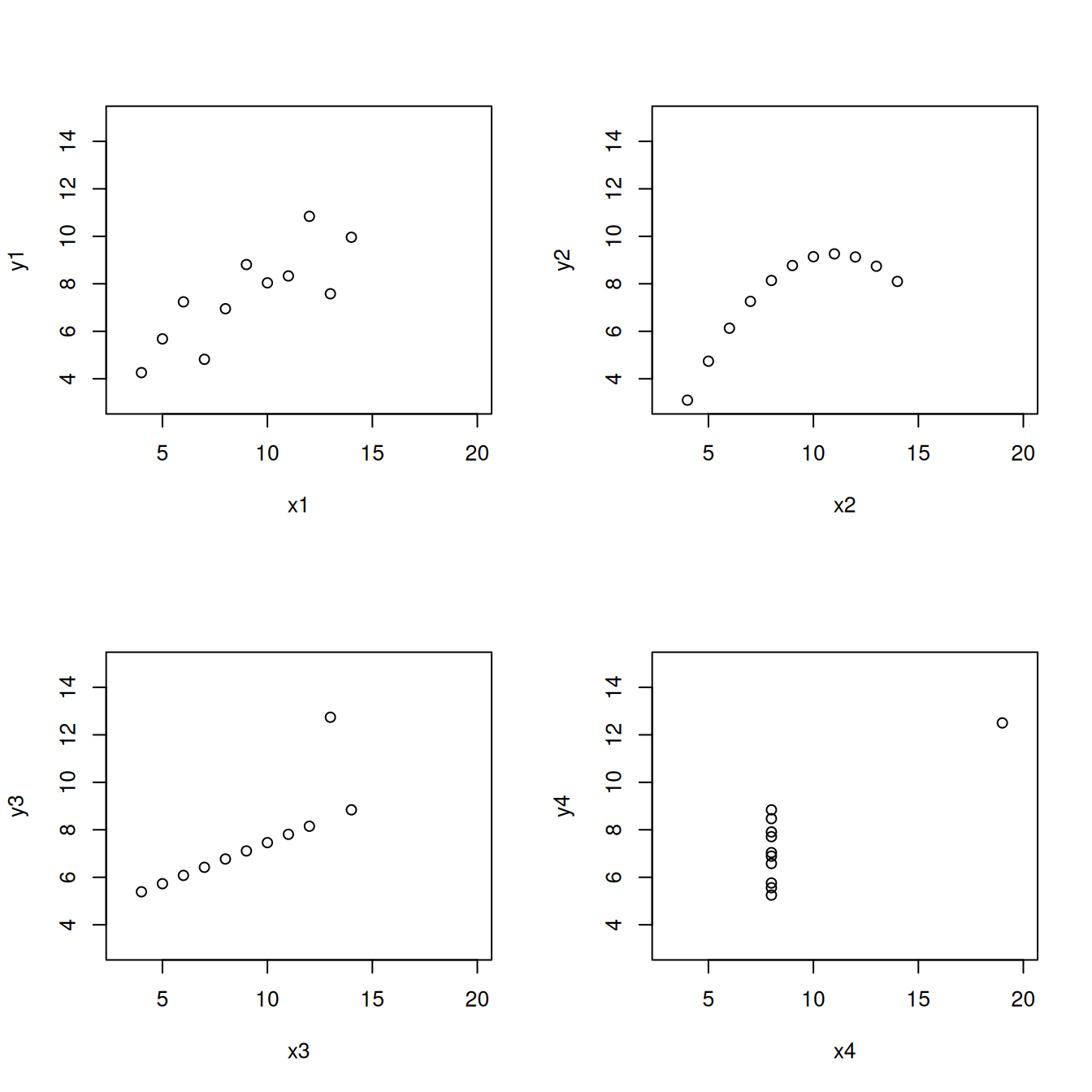
par(op) # Palautetaan alkuperäiset graafiset parametrit
cor(x1, y1)
## [1] 0.8164205
detach(anscombe) # Aineiston muuttujat irrotetaan R:n hakupolustaKorrelaatiokerroin on aina lukujen -1 ja 1 välillä. Tämä on seuraus siitä, miten korrelaatio määritellään. Satunnaismuuttujien \(X\) ja \(Y\) välinen korrelaatio on \[ \rho_{X,Y}=\frac{\mathrm{Cov}(X,Y)}{\sigma_X\sigma_Y}, \] missä \(\mathrm{Cov}(X,Y)\) on muuttujien \(X\) ja \(Y\) välinen kovarianssi, \(\sigma_X\) on muuttujan \(X\) ja \(\sigma_Y\) muuttujan \(Y\) keskihajonta.
Kovarianssi määritellään odotusarvon avulla: \[ \mathrm{Cov}(X,Y)=\mathrm{E}\left[(X-\mu_X)(Y-\mu_Y)\right], \] missä \(\mu_X=\mathrm{E}(X)\) ja \(\mu_Y=\mathrm{E}(Y)\). Muuttujan \(X\) keskihajonta on sen varianssin neliöjuuri. Varianssi on muuttujan kovarianssi itsensä kanssa: \[ \sigma_X^2=\mathrm{Var}(X)=\mathrm{E}\left[(X-\mu_X)^2\right]. \]
Tilastomuuttujien tulkitaan olevan reaalisaatioita satunnaismuuttujista. Satunnaismuuttujia kuvailevat ominaisuudet, kuten korrelaatio, voidaan estimoida havaintoaineistosta vastaavien otossuureiden eli tunnuslukujen avulla. Muuttujien \(x\) ja \(y\) otoskorrelaatio on \[ r_{xy}=\frac{\sum_{i=1}^n (x_i-\bar x)(y_i-\bar y)}{\sqrt{\sum_{i=1}^n(x_i-\bar x)^2}\sqrt{\sum_{i=1}^n(y_i-\bar y)^2}}, \] missä \(\bar x = \frac1n\sum_{i=1}^n x_i\) on muuttujan \(x\) keskiarvo ja \(\bar y = \frac1n\sum_{i=1}^n y_i\) muuttujan \(y\) keskiarvo.
1.2 Yhden selittäjän regressiomalli
Kahden muuttujan välistä lineaarista riippuvuutta voidaan kuvata suoran avulla. Yleensä tilastollisessa aineistossa riippuvuus ei ole täydellistä, jolloin pisteet eivät sijoitu täsmälleen suoralle. Kun suoran yhtälöön lisätään virhetermi, joka kuvaa \(y\)-muuttujan arvon poikkeamaa suorasta, saadaan yhden selittäjän lineaarinen regressiomalli \[ Y=\beta_0 + \beta_1 X + \epsilon. \] Muuttujaa \(Y\) kutsutaan selitettäväksi muuttujaksi (vastemuuttuja, vaste, tulosmuuttuja) ja muuttujaa \(X\) selittäväksi muutujaksi (selittäjä, ennustin, ennustava muuttuja). Mallin parametrit \(\beta_0\) ja \(\beta_1\) ovat vakioita eli ei-satunnaisia. Ne ovat yleensä tuntemattomia, ja yksi regressioanalyysin tavoite on estimoida (arvioida) niiden suuruus havaintoaineiston perusteella. Virhetermistä \(\epsilon\) oletetaan, että sen odotusarvo on 0 ja varianssi \(\sigma^2\). Yleensä se oletetaan myös normaalijakautuneeksi: \(\epsilon \sim N(0,\sigma^2)\).
Jos selittäjä \(X\) on satunnaismuuttuja, oletetaan yleensä lisäksi, että se on korreloimaton virhetermin \(\epsilon\) kanssa. Useimmiten sitä kuitenkin käsitellään kiinteänä (ei-satunnaisena), ja niin tehdään myös aluksi tällä kurssilla. Merkitään sitä sen vuoksi pienellä aakkosella \(x\).
Kun tarkastellaan \(n\) havainnon otosta, malli voidaan esittää muodossa \[ Y_i =\beta_0 + \beta_1 x_i + \epsilon_i, \quad i=1,2,...,n, \] missä alaindeksi viittaa \(i\):nteen havaintopariin. Virhetermit \(\epsilon_i\) oletetaan (tilastollisesti) riippumattomiksi.
1.3 Regressiomallin estimointi
Kun malli sovitetaan havaintoaineistoon, selitettävien ja selittävien muuttujien arvojen suhdetta kuvaa yhtälö \[ y_i = \hat\beta_0 + \hat\beta_1 x_i + e_i,\quad i=1,2,...,n. \] Hatulliset \(\hat \beta_0\) ja \(\hat \beta_1\) ovat parametrien \(\beta_0\) ja \(\beta_1\) estimaatit. Termi \(e_i\) on ns. jäännös eli residuaali, ja se voidaan tulkita virhetermin \(\epsilon_i\) estimaatiksi. Kun kaavasta pudotetaan pois jäännöstermi \(e_i\), saadaan mallin antamat sovitteet \(\hat y_i\): \[ \hat y_i = \hat\beta_0 + \hat\beta_1 x_i,\quad i=1,2,...,n. \] Sovitteet sijaitsevat estimoidulla regressiosuoralla \(y=\hat \beta_0 + \hat \beta_1 x\).
On useita tapoja estimoida tuntemattomat regressioparametrit \(\beta_0\) ja \(\beta_1\). Jos virhetermi on normaalijakautunut, monella tavalla optimaalinen menetelmä on ns. pienimmän neliösumman (PNS) menetelmä. Siinä estimaatit \(\hat \beta_0\) ja \(\hat \beta_1\) määritetään niin, että ns. virheneliösumma \[ \sum_{i=1}^n [y_i-(\hat \beta_0 + \hat \beta_1 x_i)]^2 \] minimoituu (eli saa pienimmän arvonsa). On melko helppo osoittaa, että ratkaisu saadaan yhtälöistä \[\begin{eqnarray*} \hat \beta_0 &=& \bar y - \hat \beta_1 \bar x,\\ \hat \beta_1 &=& r_{xy}\frac{s_y}{s_x}, \end{eqnarray*}\] missä \(r_{xy}\) on edellä määritelty otoskorrelaatiokerroin, ja \[ s_x=\sqrt{\frac1{n-1}\sum_{i=1}^n \left(x_i-\bar x\right)^2} \quad\mbox{ja}\quad s_y=\sqrt{\frac1{n-1}\sum_{i=1}^n \left(y_i-\bar y\right)^2} \]
ovat muuttujien \(x\) ja \(y\) otoshajonnat.
Esim. Sovitetaan R-ohjelmistoa käyttäen lineaarinen regressiomalli aineiston anscombe ensimmäiseen muuttujapariin ja piirretään regressiosuora pisteparveen.
malli1 <- lm(y1 ~ x1, data = anscombe)
malli1
##
## Call:
## lm(formula = y1 ~ x1, data = anscombe)
##
## Coefficients:
## (Intercept) x1
## 3.0001 0.5001
plot(y1 ~ x1, data = anscombe)
abline(malli1)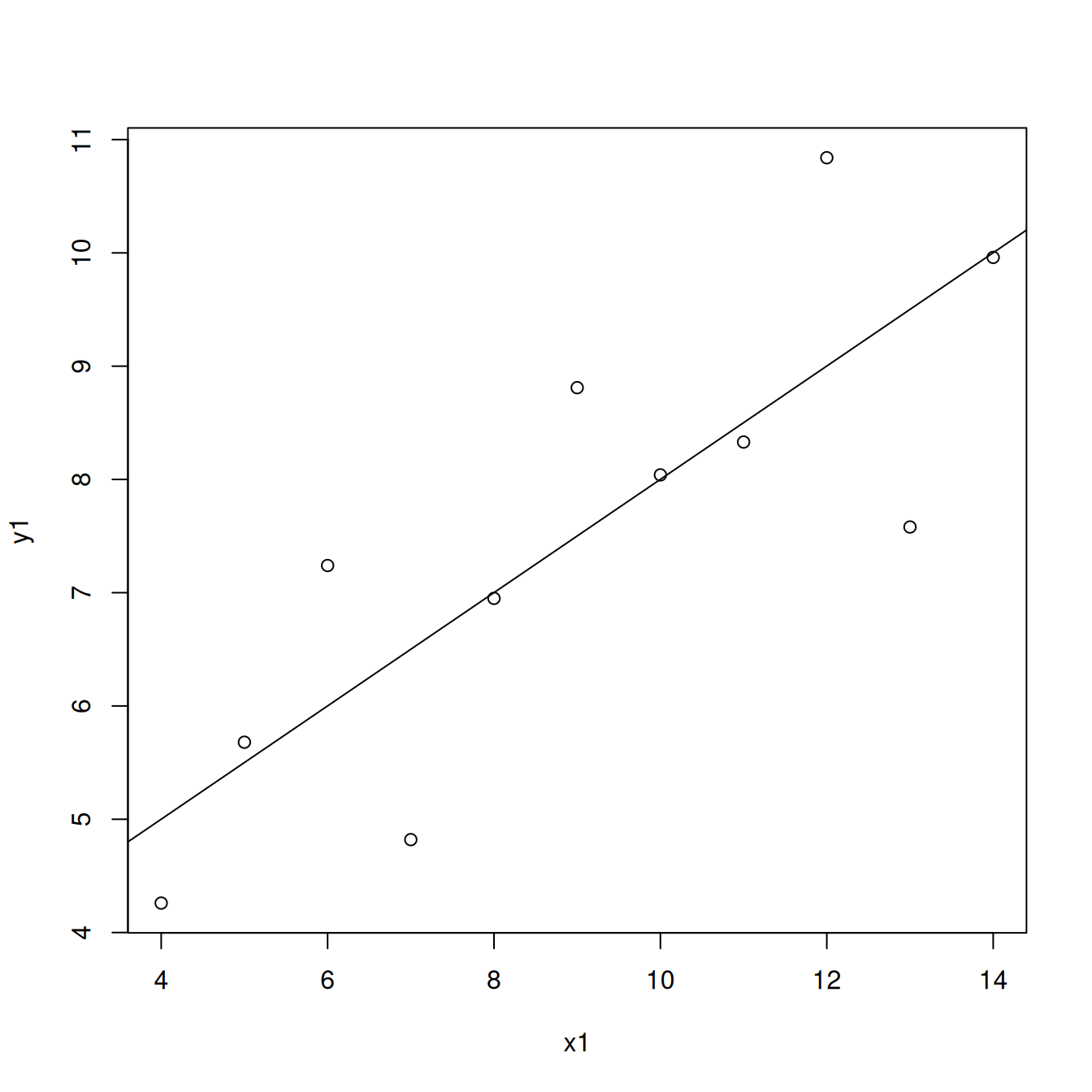
Tuloksesta nähdään, että \(\hat \beta_0 = 3.0001\) ja \(\hat \beta_1 = 0.5001\). Sovitetun regressiosuoran yhtälö on siis likimain \(y=3+0.5x\).
1.4 Regressiomallin selityskyky
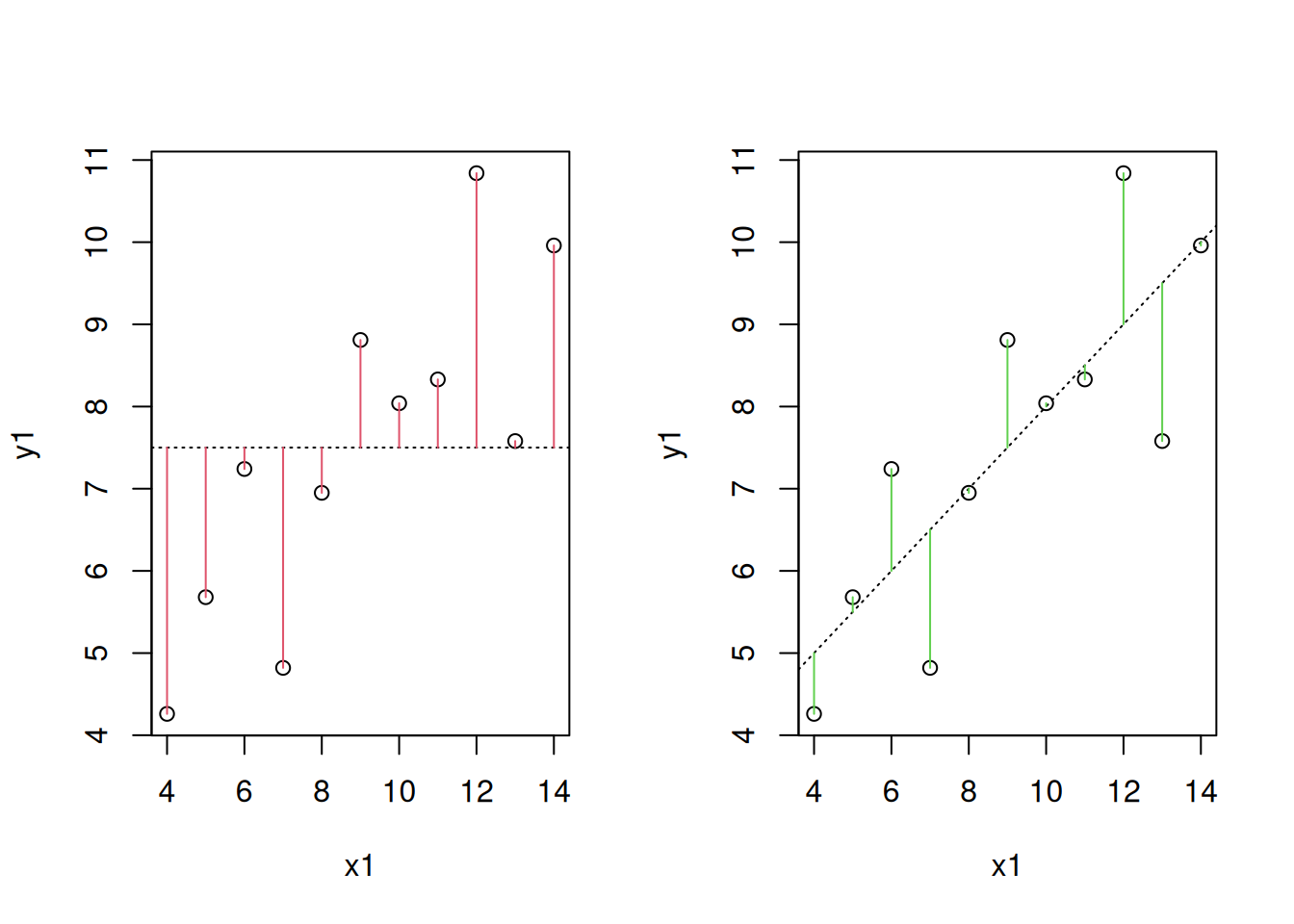
Regressiomallin selityskyky on hyvä, jos virhetermin varianssi on pieni suhteessa selitettävän muuttujan varianssiin. Virhetermin varianssin harhaton estimaattori on \(s^2=\mathrm{JNS}/(n-2)\), missä \(\mathrm{JNS}\) on ns. jäännösneliösumma: \[ \mathrm{JNS}= \sum_{i=1}^n (y_i-\hat y_i)^2. \] Se mittaa, miten paljon havainnot poikkeavat estimoidusta regressiosuorasta. Selitettävän muuttujan vaihtelua keskiarvonsa ympärillä kuvaa ns. kokonaisneliösumma \[ \mathrm{KNS}= \sum_{i=1}^n (y_i-\bar y)^2. \] Näiden neliösummien avulla voidaan laskea ns. selitysaste \[\begin{equation} \mathrm{R}^2 = \frac{\mathrm{KNS}-\mathrm{JNS}}{\mathrm{KNS}} = 1- \frac{\mathrm{JNS}}{\mathrm{KNS}}. \tag{1.1} \end{equation}\] Jos mallin sopivuus on hyvä, jäännösneliösumma on pieni suhteessa kokonaisneliösummaan ja \(\mathrm{R}^2\) on lähellä ykköstä. Mutta jos mallin sopivuus on huono, jäännösneliösumma on lähellä kokonaisneliösummaa ja selitysaste on lähellä nollaa. Voidaan osoittaa, että yhden selittäjän tapauksessa selitysaste on sama kuin korrelaatiokertoimen neliö: \(\mathrm{R}^2=r_{xy}^2\).
Seuraavissa kuvioissa on vasemmalla näytetty selitettävän muuttujan poikkeamat keskiarvosta ja oikealla poikkeamat regressiosuorasta. Tässä on jälleen käytetty anscombe-aineiston ensimmäisiä muuttujia.
1.5 Testaaminen
Regressioanalyysin avulla voidaan tutkia, onko selitettävän ja selittäjän välillä todellista yhteyttä vai onko yhteys näennäinen. Tämä voidaan tehdä testaamalla, onko regressiokerroin \(\beta_1\) yhtä suuri kuin nolla mallissa \(Y_i = \beta_0 + \beta_1 x_i +\epsilon_i\). Tämä testi on yhtäpitävää sen testaamisen kanssa, onko korrelaatiokerroin \(\rho_{XY}\) nolla.
Testaaminen perustuu estimaattorin \(\hat \beta_1\) jakaumaan. (Estimaattori on satunnaismuuttuja, koska se on laskettu satunnaisotoksesta eli on sen funktio.) Klassisen regressiomallin oletusten vallitessa \(\hat \beta_1\) on normaalijakautunut. Kun siitä vähennetään sen odotusarvo \(\beta_1\) ja jaetaan sen estimoidulla keskihajonnalla eli keskivirheellä, saadaan t-jakautunut satunnaismuuttuja: \[ \frac{\hat\beta_1-\beta_1}{s_{\hat \beta_1}} \sim t(n-2). \] Tästä seuraa, että jos hypoteesi \(H_0:\ \beta_1 = 0\) on tosi, t-testisuure \(t=\hat \beta_1/s_{\hat \beta_1}\) on t-jakautunut \(n-2\) vapausasteella. Jos testisuureen itseisarvo on suurempi kuin t-jakauman kriittinen arvo \(t_{1-\alpha/2;n-2}\) (t-jakauman kvantiilifunktio kohdassa \(1-\alpha/2\)), nollahypoteesi hylätään riskitasolla \(100\cdot\alpha\ \%\) kaksipuoleisessa testissä.
Tilasto-ohjelmat yleensä tulostavat estimaatin sekä sen keskivirheen, t-arvon ja P-arvon. Ohjelmat antavat vastaavat luvut myös vakiotermin \(\beta_0\) estimaatille, mutta sen testaamisesta ei yleensä olla kiinnostuneita.
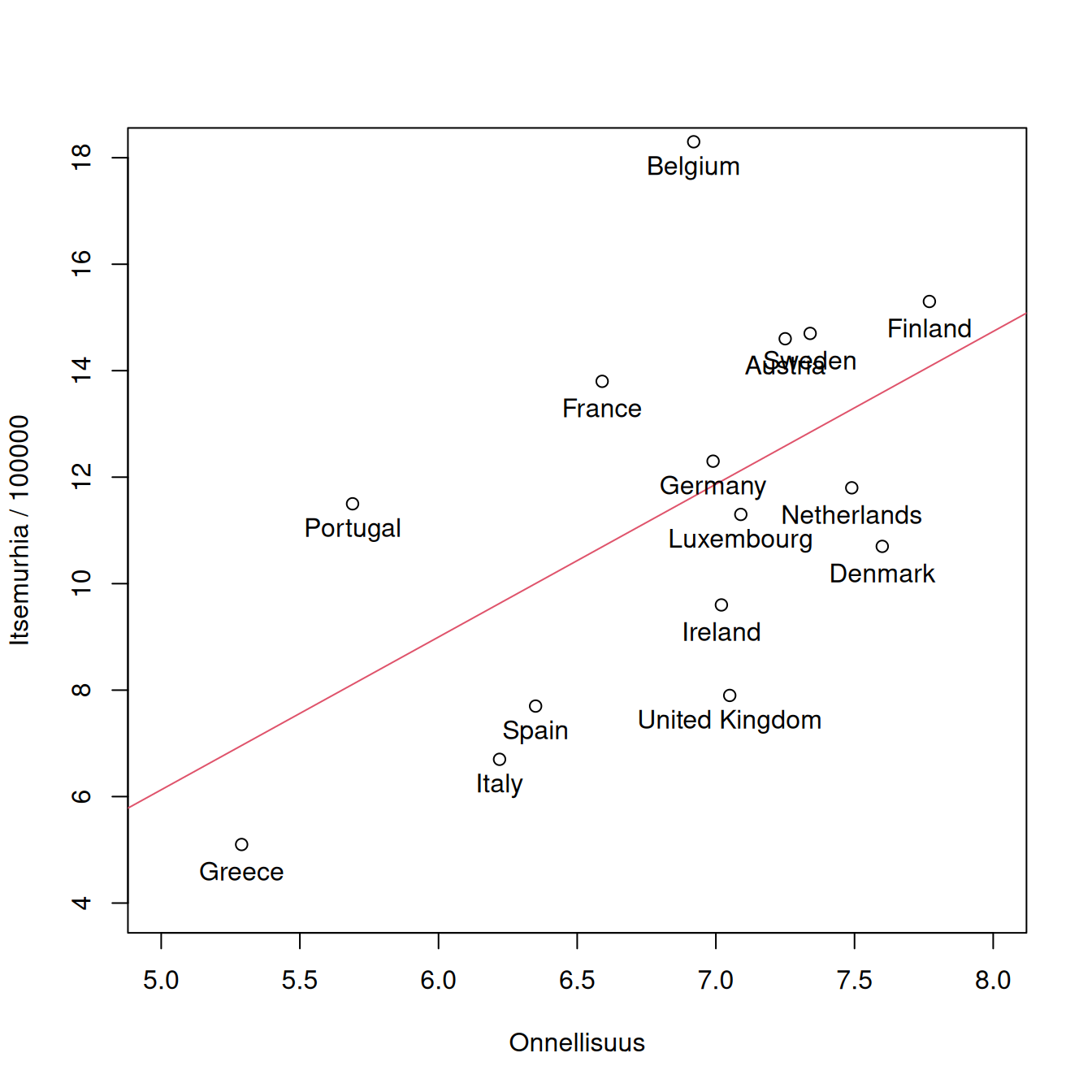
Esim. Daly ja muut (Daly et al. 2011) tutkivat onnellisuuspistemäärä ja itsemurhaintensiteetin välistä yhteyttä ja päätyivät epäloogiselta vaikuttavaan tulokseen. Seuraavassa sirontakuviossa ovat samat Euroopan maat mutta aineisto on uudempi, vuodelta 2019. Sovitetaan lineaarinen regressiomalli ja tarkastellaan tuloksia.
itsem <- read.table("../datat/onni_itsem.csv", header = TRUE, sep = ",")
osa <- c("FIN", "DNK", "SWE", "DEU", "FRA", "AUT", "GRC", "ITA", "PRT",
"GBR", "IRL", "ESP", "NLD", "BEL", "LUX")
itsem_osa <- itsem[itsem$Code %in% osa,]
malli2 <- lm(SuicideRate ~ HappinessIndex, data = itsem_osa)
with(itsem_osa, {
plot(HappinessIndex, SuicideRate, xlim = c(5, 8), ylim = c(4, 18),
xlab = "Onnellisuus", ylab= "Itsemurhia / 100000")
abline(malli2, col = 2)
text(HappinessIndex, SuicideRate - 0.5, labels = Country)}
)
R:n summary-funktio tulostaa tarvittavat tiedot:
summary(malli2)
##
## Call:
## lm(formula = SuicideRate ~ HappinessIndex, data = itsem_osa)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.111 -2.314 -0.826 1.936 6.662
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -8.222 8.161 -1.008 0.332
## HappinessIndex 2.870 1.187 2.419 0.031 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.109 on 13 degrees of freedom
## Multiple R-squared: 0.3103, Adjusted R-squared: 0.2573
## F-statistic: 5.85 on 1 and 13 DF, p-value: 0.03098Tulosteesta nähdään ensiksi tunnuslukuja jäännöstermin jakaumasta, Jäännökset ovat välillä [-4.111, 6.662]. Sovitettu malli voidaan esittää muodossa \[\begin{eqnarray*} y & = & -8.222 + 2.870 x + e,\\ & & \ (8.161) \ \ (1.187) \end{eqnarray*}\] missä \(y\) on itsemurhien määrä 100 000 asukasta kohden ja \(x\) onnellisuusindeksi (joka saa arvoja 0 ja 10 väliltä). Estimaattien keskivirheet on annettu sulkeissa. Koska p-arvo 0.031 on pienempi kuin 0.05, nollahypoteesi, että regressiokerroin on nolla, hylätään riskitasolla 0.05. Yksi tähti (*) tarkoittaa sitä, että p-arvo on pienempi kuin 0.05 mutta suurempi kuin 0.01. Tulos kertoo, että kun onnellisuusindeksi kasvaa yhdellä, itsemurhien lukumäärä 100 000 henkeä kohti kasvaa lähes 3:lla. Kun malli on esitetty tässä muodossa, vakiotermillä ei ole mielekästä tulkintaa.
Tuloksista nähdään myös, että jäännöstermin hajonta on \(s=3.109\) ja selitysaste on \(\mathrm{R}^2=0.3103\). Onnellisuus näyttäisi siis selittävän 31 % itsemurhaintensiteetin vaihtelusta! Tuloksista voidaan myös päätellä, että havaintojen lukumäärä on \(n=15\), koska vapausasteiden lukumäärä on \(n-2=13\). Muokattuun selitysasteeseen (adjusted \(\mathrm{R}^2\)) ja \(F\)-testisuureeseen palaamme myöhemmin.
Estimoidaan malli vielä hiukan toisessa muodossa niin, että vakiokertoimelle tulee mielekäs tulkinta. Käytetään selittäjänä keskistettyä onnellisuusindeksiä eli siis muuttujaa, joka saadaan vähentämällä onnettomuusindeksistä sen keskiarvo.
lm(SuicideRate ~ I(HappinessIndex - mean(HappinessIndex)), data = itsem_osa)
##
## Call:
## lm(formula = SuicideRate ~ I(HappinessIndex - mean(HappinessIndex)),
## data = itsem_osa)
##
## Coefficients:
## (Intercept)
## 11.42
## I(HappinessIndex - mean(HappinessIndex))
## 2.87Sovitettu malli on \[ y = 11.42 + 2.87(x-\bar x)+ e. \] Vakiotermi on nyt 11.42. Se on mallin ennustama arvo itsemurhaintensiteetille, kun onnellisuusindeksi on keskiarvossaan. Itse asiassa 11.42 on sama kuin itsemurhaintensiteetin keskiarvo, sillä regressiosuora kulkee keskiarvopisteen \((\bar x, \bar y)\) kautta.
1.6 Regressio kohti keskiarvoa
Ensimmäinen, joka tiedetysti teki regressioanalyysiä oli Francis Galton 1877. Hän tutki, millainen riippuvuus herneen siemenen läpimitassa on “vanhempien” ja “jälkipolven” välillä (parent seed ja offspring seed). Hän havaitsi, että jos vanhemman siemen on keskimääräistä pienempi, jälkeläisen siemen on myös keskimääräistä pienempi mutta ei kuitenkaan yhtä paljon kuin vanhempansa. Jos vanhemman siemen on keskimääräistä suurempi, jälkeläisen siemen on myös muttei kuitenkaan yhtä paljon kuin vanhempansa. Tapahtuu siis regressio (palautuminen, taantuminen) kohti keskiarvoa. Myöhemmin v. 1886 hän tutki (ihmisillä) yhteyttä vanhempien pituuksien painotetun keskiarvon (ns. keskivanhemman pituuden) ja lasten pituuden välilllä ja havaitsi saman ilmiön.
Näissä tilanteissa on kyse siitä, että sekä selitettävä että selittävä muuttuja mittaavat samaa ominaisuutta yksilöiltä, jotka ovat jollain tavoin sidoksissa toisiinsa. Voisi kuvitella, että regression vuoksi vähitellen ominaisuuden, esim. pituuden, jakauma supistuisi kohti keskiarvoa. Näin ei kuitenkaan käy ilmiöön liittyvän satunnaisuuden vuoksi, vaan ominaisuuden vaihtelu pysyy samanlaisena. Monissa ilmiöissä (ks. esimerkkejä Peren monisteesta) voisi luulla tapahtuvan “taantumista” vaikka niin ei todellisuudessa tapahdu.
Linkin shiny-sovellus havainnollistaa ilmiötä. Esimerkkinä tarkastellaan vanhemman ja lapsen älykkyysosamäärän korrelaatiota. Sovelluksessa voi säätää korrelaatiokerrointa ja havaintojen lukumäärää.