Luku 3 Varianssianalyysi
Varianssianalyysistä puhutaan silloin, kun vastemuuttuja on normaalijakautunut mutta selittäjät luokitteluasteikollisia. Kun selittäjiä on yksi, puhutaan yksisuuntaisesta varianssianalyysistä, ja kun niitä on kaksi, kaksisuuntaisesta varianssianalyysistä jne. Nimestään huolimatta varianssianalyysin varsinainen tavoite ei ole varianssien analysointi vaan odotusarvojen yhtäsuuruuden testaaminen. Nimitys viittaa siihen, että vastemuuttujan varianssi jaetaan komponentteihin, jotka liittyvät vaihtelun eri lähteisiin.
Luokitteluasteikollisista selittäjistä käytetään usein nimitystä faktori. (Tällä ei ole mitään tekemistä faktorianalyysin kanssa, jossa faktori-sanalla on aivan eri merkitys!) Jos selittäjänä on lisäksi jokin jatkuva-arvoinen muuttuja, kyseessä on kovarianssianalyysi.
3.1 Yksisuuntainen varianssianalyysi
Yksisuuntaisessa varianssianalyysissä on yksi luokitteluasteikollinen selittäjä. Mallissa oletetaan, että havainnot \(Y_{ij}\) ovat riippumattomia ja \[ Y_{ij} \sim N(\mu_i,\sigma^2),\quad i=1,...,m,\quad j=1,..,n_i, \] missä alaindeksi \(i\) on luokan järjestysluku, \(j\) havainnon järjhestysluku luokassa \(i\) ja \(\mu_i\) havaintojen odotusarvo luokassa \(i\). Nollahypoteesina on, että odotusarvo on sama kaikissa luokissa: \[ H_0:\ \mu_1 = ... = \mu_m. \] Vaihtoehtoinen hypoteesi on, että ainakin kaksi odotusarvoa poikkeaa toisistaan.
Lasketaan ensin luokkakohtaiset keskiarvot \(\bar y_i = (\sum_{j=1}^{n_i} y_{ij})/n_i\) ja kokonaiskeskiarvo \(\bar y= (\sum_{i=1}^m\sum_{j=1}^{n_i} y_{ij})/n\), missä \(n=n_1+...+n_m\) on kaikkien havaintojen lukumäärä. Yksittäisen havainnon poikkeama kokonaiskeskiarvosta voidaan nyt esittää summana \[ y_{ij}-\bar y = (\bar y_i-\bar y)+ (y_{ij}-\bar y_i). \] Neliöimällä tämä yhtälö puolittain ja summaamalla havaintojen yli saadaan neliösummahajotelma \[ \sum_{i=1}^m \sum_{j=1}^{n_i} (y_{ij}-\bar y)^2 = \sum_{i=1}^m n_i (\bar y_i-\bar y)^2+\sum_{i=1}^m \sum_{j=1}^{n_i} (y_{ij}-\bar y_i)^2, \] eli \[ \mbox{KNS}=\mbox{LNS}+\mbox{JNS}, \] missä KNS on kokonaisneliösumma, LNS on luokkaneliösumma ja JNS jäännösneliösumma.
Oletuksista seuraa, että LNS ja JNS ovat riippumattomia ja että \(\mbox{JNS}/\sigma^2 \sim \chi^2(n-m)\). Jos lisäksi nollahypoteesi on tosi, \(\mbox{LNS}/\sigma^2 \sim \chi^2(m-1)\). Näistä seuraa, että jos nollahypoteesi on tosi, \[ F=\frac{\mathrm{LNS}/(m-1)}{\mathrm{JNS}/(n-m)}\sim F(m-1,n-m). \] Tätä testisuuretta voidaan käyttää \(H_0\):n testaamisessa.
Varianssianalyysin tulos esitetään usein taulukkomuodossa:
| vaihtelu | neliösumma | vapausast. | keskineliösumma | F |
|---|---|---|---|---|
| luokka | LNS | \(m-1\) | \(\mathrm{LNS}/(m-1)\) | \([\mathrm{LNS}/(m-1)]/[\mathrm{JNS}/(n-m)]\) |
| jäännös | JNS | \(n-m\) | \(\mathrm{JNS}/(n-m)\) | |
| kokonais | KNS | \(n-1\) | \(\mathrm{KNS}/(n-1)\) |
Esim. Sokerijuurikaskoe (Lawson 2015). Rothamsteadin tutkimusasemalla tehtiin 1937 sokerijuurikkaan kasvatukseen liittyvä koe, jonka tarkoituksena oli selvittää kylvämisajan ja keinolannoitesekoituksen (NPK) käyttötavan vaikutusta satoon. Yleensä lannoitetta levitetään ja siemenet kylvetään niin aikaisin kuin maata voidaan työstää. Koeyksikköinä olivat peltolohkot, joihin kuhunkin sovellettiin yhtä seuraavista menetelmistä:
- keinolannoitetta ei käytetty
- keinolannoitetta käytettiin tammikuussa (kyntö)
- keinolannoitetta käytettiin tammikuussa (hajalevitys)
- keinolannoitetta käytettiin huhtikuussa (hajalevitys)
Vastemuuttujana oli sato yksikkönä sentneri (swt) eekkeriä kohti. Koetta varten valittiin 18 peltolohkoa, jolloin kutakin käsittelyä vastasi neljä tai viisi satunnaisesti valittua peltolohkoa.
Seuraavassa R-koodissa käytetään aineistoa sugarbeet, jonka muuttuja yield on vastemuuttuja ja treat on käsittelymuuttuja. Muuttujan treat luokka on factor, mikä tarkoittaa sitä, että se on määritelty luokitteluasteikolliseksi.
library(daewr) # Paketti daewr sisältää kirjan 'Design and Analysis of
# Experiments with R' aineistoja
plot(yield ~ treat, data = sugarbeet) # Laatikkokuvio aineistosta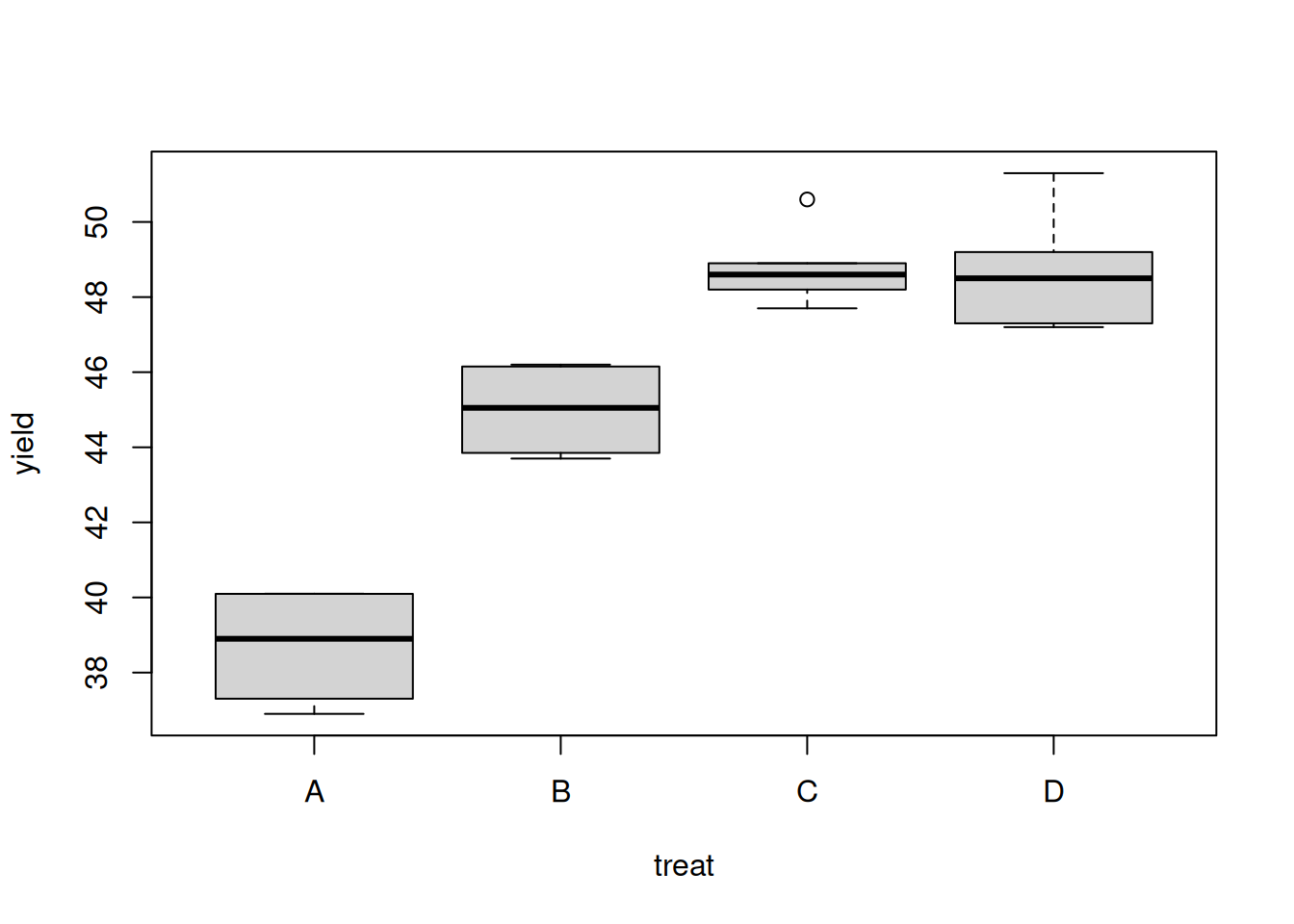
# Tehdään yksisuuntainen varianssianalyysi (1-VA)
malli1 <- aov(yield ~ treat, data = sugarbeet)
summary(malli1)
## Df Sum Sq Mean Sq F value Pr(>F)
## treat 3 291.00 97.00 45.9 1.72e-07 ***
## Residuals 14 29.59 2.11
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Tulos on tässä annettu varianssianalyysitaulukon muodossa. Näemme, että tulos on erittäin merkitsevä. Nollahypoteesi, että viljelymenetelmillä ei ole eroa, hylätään. Saamme näkyviin kokonaiskeskiarvon ja luokkakeskiarvot model.tables-funktiolla:
model.tables(malli1, type = "means")
## Tables of means
## Grand mean
##
## 45.68333
##
## treat
## A B C D
## 38.7 45 48.8 48.7
## rep 4.0 4 5.0 5.0Malli voidaan esittää myös lineaarisen regressiomallin muodossa: \[ Y_{ij}=\beta_0+\beta_2x_{2j}+...+\beta_m x_{mj}+\epsilon_{ij}, \] missä \(x_{ij}\) on osoitinmuuttuja, joka saa arvon 1, kun havainto kuuluu luokkaan \(i\), ja 0 muuten. Ensimmäinen luokka on vertailuluokka, ja se ei tarvitse osoitinmuuttujaa. Vakiotermi \(\beta_0\) on vastemuuttujan odotusarvo vertailuluokassa, ja regressiokerroin \(\beta_i,\ i=2,...,m,\) on \(i\). luokan ja vertailuluokan odotusarvojen erotus.
Esim. Estimoidaan edellisen esimerkin malli vielä regressiomallina:
malli1b <- lm(yield ~ treat, data = sugarbeet)
summary(malli1b)
##
## Call:
## lm(formula = yield ~ treat, data = sugarbeet)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.800 -1.075 -0.200 1.175 2.600
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 38.7000 0.7269 53.242 < 2e-16 ***
## treatB 6.3000 1.0279 6.129 2.61e-05 ***
## treatC 10.1000 0.9752 10.357 6.04e-08 ***
## treatD 10.0000 0.9752 10.254 6.84e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.454 on 14 degrees of freedom
## Multiple R-squared: 0.9077, Adjusted R-squared: 0.8879
## F-statistic: 45.9 on 3 and 14 DF, p-value: 1.718e-07Tuloksista näemme, että \(F\)-testisuure saa saman arvon kuin edellisessäkin tapauksessa. Näemme myös, että viljelymenetelmät B, C ja D antavat erittäin merkitsevästi paremman sadon kuin vertailumenetelmä A, jossa ei käytetty lainkaan lannoitteita.
Jos haluamme testata, onko menetelmillä B ja C eroa, helpointa on tehdä se muuttamalla B vertailutasoksi. Tuloksesta näemme, että menetelmät A, C ja D eroavat merkitsevästi menetelmästä B.
sugarbeet$treat <- relevel(sugarbeet$treat, "B")
malli1c <- lm(yield ~ treat, data = sugarbeet)
summary(malli1c)
##
## Call:
## lm(formula = yield ~ treat, data = sugarbeet)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.800 -1.075 -0.200 1.175 2.600
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 45.0000 0.7269 61.910 < 2e-16 ***
## treatA -6.3000 1.0279 -6.129 2.61e-05 ***
## treatC 3.8000 0.9752 3.897 0.00161 **
## treatD 3.7000 0.9752 3.794 0.00197 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.454 on 14 degrees of freedom
## Multiple R-squared: 0.9077, Adjusted R-squared: 0.8879
## F-statistic: 45.9 on 3 and 14 DF, p-value: 1.718e-073.2 Kaksisuuntainen varianssianalyysi
Kaksisuuntaisessa varianssianalyysissä on kaksi luokitteluasteikollista selittäjää; olkoot ne \(x\) ja \(z\). Havaintoarvon jakauma on \[ Y_{ijk} \sim N(\mu_{ij},\sigma^2) \] missä \(i=1,...,I\) on muuttujan \(x\) luokan indeksi, \(j=1,...,J\) on muuttujan \(z\) luokan indeksi ja \(k=1,...,n_{ij}\) on yksittäisen havainnon indeksi solussa \((i,j)\). Odotusarvoja selittäjien eri luokissa kuvaa seuraava taulukko:
| \(z_1\) | … | \(z_J\) | |
|---|---|---|---|
| \(x_1\) | \(\mu_{11}\) | … | \(\mu_{1J}\) |
| … | … | … | … |
| \(x_I\) | \(\mu_{I1}\) | … | \(\mu_{IJ}\) |
Odotusarvot voidaan jakaa yhteenlaskettaviin osiin seuraavasti: \[ \mu_{ij}=\mu + \alpha_i + \beta_j + \gamma_{ij}, \] missä \(\mu\) on kokonaisodotusarvo, \(\alpha_i\) muuttujan \(x\) omavaikutus, \(\beta_j\) muuttujan \(z\) omavaikutus ja \(\gamma_{ij}\) yhteisvaikutus. Jotta parametrit olisivat määritellyt yksikäsitteisesti, oletetaan, että \(\sum_{i=1}^I \alpha_i=0\), \(\sum_{j=1}^J \beta_j=0,\) \(\sum_{i=1}^I\gamma_{ij}=0\) ja \(\sum_{j=1}^J\gamma_{ij}=0\).
Malli voidaan esittää regressiomallina seuraavasti: \[ Y = \beta_0 + \sum_{i=2}^I \beta_i x_i + \sum_{j=2}^J\gamma_j z_j + \sum_{i=2}^I \sum_{j=2}^J \delta_{ij} x_i z_j+\epsilon, \] missä \(x_i\) on osoitinmuuttuja sille, että \(x\)-muuttuja kuuluu luokkaan \(i\), ja \(z_j\) on osoitinmuuttuja sille, että \(z\)-muuttuja kuuluu luokkaan \(j\). Tässä mallissa vakiotermi \(\beta_0\) on vasteen odotusarvo, kun \(i=j=1\) eli molemmat selittäjät ovat vertailuluokassaan. Parametrit \(\beta_i\) ovat selittäjän \(x\) omavaikutuksia, ja ne kuvaavat odotusarvon muutosta, kun selittäjän \(x\) luokka vaihtuu vertailuluokasta luokkaan \(i\). Vastaavasti parametrit \(\gamma_j\) ovat muuttujan \(z\) omavaikutuksia. Yhteisvaikutukset \(\delta_{ij}\) selittävät sen osuuden erotuksesta \(\mu_{ij}-\mu_{11}\) , mitä omavaikutukset eivät selitä.
Kaksisuuntaisessa varianssianalyysissä tyypillisesti testataan omavaikutusten ja yhteisvaikutusten olemassaoloa. Malli rakennetaan hierarkkisesti niin, että jos siinä ovat mukana yhteisvaikutukset, siinä ovat mukana myös molemmat päävaikutukset.
Esim. CO-päästöaineiston analyysi R:llä. Tulokset ovat kahden faktorin (selittävän muuttujan) kokeesta (Hunter 1983). Kokeessa poltettiin tietty määrä polttoainetta ja määritettiin CO-päästö. Vastemuuttujana on CO-konsentraatio (\(g/m^3\)). Faktori \(x\) on lisätyn etanolin määrä ja faktori \(y\) ilma-polttoaine-suhde. Kullakin faktorikombinaatiolla tehtiin kaksi toistoa. Aineisto COdata sisältyy R-pakettiin daewr.
library(daewr)
malli1 <- aov(CO ~ Eth * Ratio, data = COdata)
# Merkintä Eth * Ratio tarkoittaa, että mallissa on mukana omavaikutusten lisäksi yhteisvaikutus
# Malli voidaan myös esittää: CO ~ Eth + Ratio + Eth:Ratio
summary(malli1)
## Df Sum Sq Mean Sq F value Pr(>F)
## Eth 2 324.0 162.0 31.36 8.79e-05 ***
## Ratio 2 652.0 326.0 63.10 5.07e-06 ***
## Eth:Ratio 4 678.0 169.5 32.81 2.24e-05 ***
## Residuals 9 46.5 5.2
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Varianssianalyysitaulukossa on omat neliösummat molemmille omavaikutuksille sekä yhteisvaikutuksille. Vaikutuksia testataan F-testeillä. Niiden perusteella kaikki vaikutukset ovat erittäin merkitseviä. Seuraavista taulukoista nähdään vastemuuttujan keskiarvot faktorien eri tasoilla.
model.tables(malli1, type = "means")
## Tables of means
## Grand mean
##
## 72.83333
##
## Eth
## Eth
## 0.1 0.2 0.3
## 66.83 75.83 75.83
##
## Ratio
## Ratio
## 14 15 16
## 78.5 75.5 64.5
##
## Eth:Ratio
## Ratio
## Eth 14 15 16
## 0.1 64.0 69.5 67.0
## 0.2 79.5 80.5 67.5
## 0.3 92.0 76.5 59.0Tuloksia voidaan havainnollistaa yhteisvaikutuskuviolla.
op <- par(mfrow = c(1,2))
with(COdata,{
interaction.plot(Eth, Ratio, CO, type = "b", pch = c(18, 24, 22), leg.bty = "o")
interaction.plot(Ratio, Eth, CO, type = "b", pch = c(18, 24, 22), leg.bty = "o")
})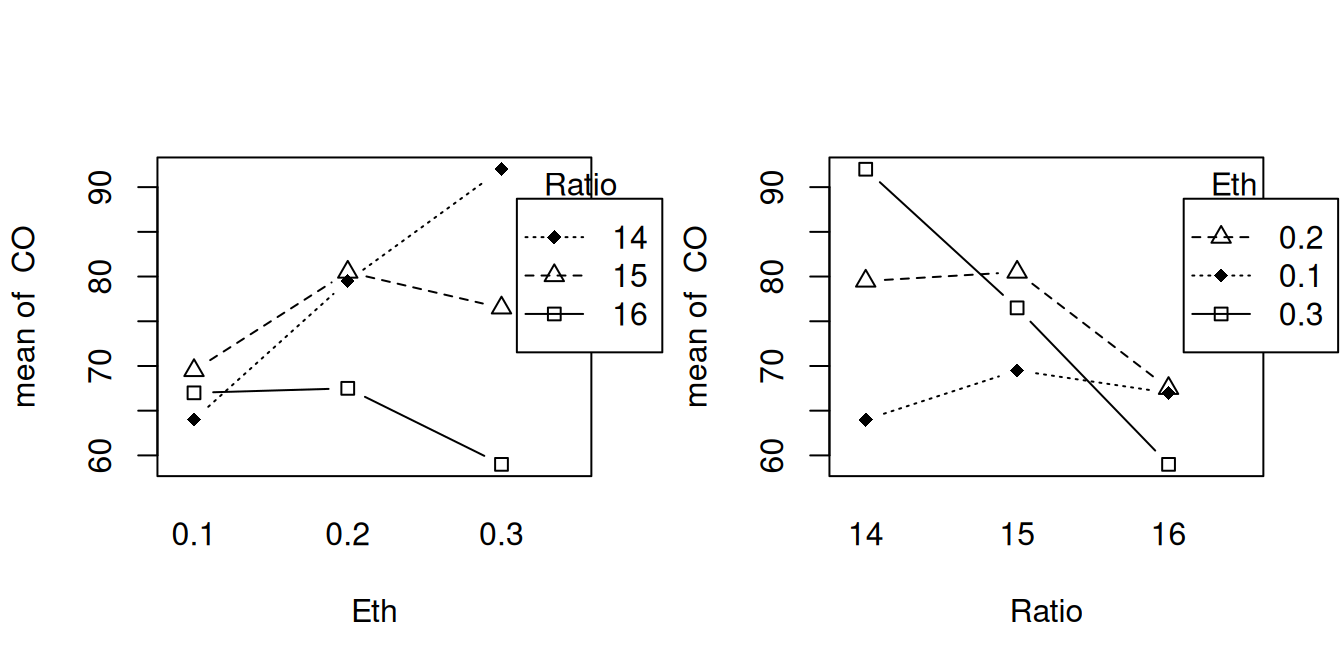 Kuvioista nähdään, että faktoreilla on yhteisvaikutusta, koska murtoviivat eivät ole yhdensuuntaisia. Vasemmanpuoleisessa kuvioissa vaaka-akselilla on lisätyn etanolin määrä ja eri murtoviivat vastaavat ilma-polttoaine-suhteen eri tasoja. Oikeanpuoleisessa kuvioissa vaaka-akselilla on ilma-polttoaine-suhde ja eri murtoviivat vastaavat lisätyn etanolin määrän eri tasoja. Kummassakin kuviossa pystyakselilla on vastemuuttuja CO-konsentraatio. Kummastakin kuviosta nähdään, että tutkituista vaihtoehdoista pienin päästö saavutetaan, kun lisätyn etanolin määrä on 0.3 ja ilma-polttoaine-suhde on 16.
Kuvioista nähdään, että faktoreilla on yhteisvaikutusta, koska murtoviivat eivät ole yhdensuuntaisia. Vasemmanpuoleisessa kuvioissa vaaka-akselilla on lisätyn etanolin määrä ja eri murtoviivat vastaavat ilma-polttoaine-suhteen eri tasoja. Oikeanpuoleisessa kuvioissa vaaka-akselilla on ilma-polttoaine-suhde ja eri murtoviivat vastaavat lisätyn etanolin määrän eri tasoja. Kummassakin kuviossa pystyakselilla on vastemuuttuja CO-konsentraatio. Kummastakin kuviosta nähdään, että tutkituista vaihtoehdoista pienin päästö saavutetaan, kun lisätyn etanolin määrä on 0.3 ja ilma-polttoaine-suhde on 16.Katsotaan vielä tuloksia, kun malli on estimoitu regressiomallina:
##
## Call:
## lm(formula = CO ~ Eth * Ratio, data = COdata)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.5 -1.5 0.0 1.5 2.5
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 64.000 1.607 39.819 1.98e-11 ***
## Eth0.2 15.500 2.273 6.819 7.74e-05 ***
## Eth0.3 28.000 2.273 12.318 6.16e-07 ***
## Ratio15 5.500 2.273 2.420 0.038631 *
## Ratio16 3.000 2.273 1.320 0.219477
## Eth0.2:Ratio15 -4.500 3.215 -1.400 0.195062
## Eth0.3:Ratio15 -21.000 3.215 -6.533 0.000107 ***
## Eth0.2:Ratio16 -15.000 3.215 -4.666 0.001175 **
## Eth0.3:Ratio16 -36.000 3.215 -11.199 1.38e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.273 on 9 degrees of freedom
## Multiple R-squared: 0.9727, Adjusted R-squared: 0.9483
## F-statistic: 40.02 on 8 and 9 DF, p-value: 3.861e-06Sovitettu malli on siis: \[ y=64 + 15.5x_2+28x_3+5.5z_2+3z_3-4.5x_2z_2-21x_3z_2-15x_2z_3-36x_3z_3 + e, \] missä \(x_j\):t ovat faktorin Eth ja \(z_j\):t faktorin Ratio eri tasojen osoittimia.