Luku 2 Monen selittäjän regressiomalli
Monen selittäjän lineaarinen regressiomalli voidaan esittää muodossa \[ Y = \beta_0 +\beta_1 x_1 + ... + \beta_k x_k + \epsilon, \] missä \(Y\) on selitettävä muuttuja (vastemuuttuja), muuttujat \(x_1, x_2, ..., x_k\) ovat selittäjiä ja \(\epsilon\) on virhetermi. Oletamme tässä, että selittäjät \(x_j,\ j=1,...,k,\) ovat kiinteitä (ei-satunnaisia) ja että virhetermi on normaalijakautunut: \(\epsilon\sim N(0,\sigma^2)\).
2.1 Regressiomallin estimointi ja selityskyky
Regressioanalyysissä estimoidaan vakiotermi \(\beta_0\) ja regressiokertoimet \(\beta_1,...,\beta_k\). Aineistona on \(n\) havaintovektoria \((x_{11},...,x_{1k},y_1),..., (x_{n1},...,x_{nk},y_n)\). Merkinnässä \((x_{i1},...,x_{ik},y_i)\) indeksi \(i\) viittaa rivin järjestyslukuun, jos havaintovektorit on järjestetty alakkain havaintomatriisiksi. Jotta estimointi olisi mahdollista, selittäjiä vastaavat havaintomatriisin sarakkeet eivät saa olla lineaarisesti riippuvia. Kuten yhden selittäjän tapauksessa, oletamme, että eri havaintoja vastaavat virhetermit \(\epsilon_1,...,\epsilon_n\) ovat riippumattomia ja noudattavat jakaumaa \(N(0,\sigma^2)\).
Malli sovitetaan yleensä PNS-menetelmällä. Siinä parametrit \(\beta_0,...,\beta_k\) määritetään niin, että virheneliösumma \[ \sum_{i=1}^n [y_i-(\beta_0+\beta_1 x_{i1}+...+\beta_k x_{ik})]^2 \] minimoituu. Estimoitu malli antaa selitettävälle muuttujalle sovitteet \[ \hat y_{i}= \hat \beta_0 + \hat \beta_1 x_{i1} + ...+ \hat \beta_k x_{ik},\ i=1,...,n, \] missä \(\hat \beta_0,..., \hat\beta_k\) ovat PNS-estimaatit parametreille.
Sovitettu malli antaa jäännökset \(e_i=y_i-\hat y_i,\ i=1,...,n,\) joiden avulla voidaan laskea jäännösneliösumma \[ JNS = \sum_{i=1}^n (y_i-\hat y_i)^2 \] virhetermin varianssin estimaatti \[ s^2 = \frac{1}{n-k-1} \sum_{i=1}^n (y_i-\hat y_i)^2. \] Mallin selitysaste \(R^2\) voidaan laskea jäännös- ja kokonaisneliösummasta samoin kuin yhden selittäjän tapauksessa; ks. kaava (1.1). Voidaan myös osoittaa, että selitysaste on yhtä suuri kuin (otoksesta lasketun) yhteiskorrelaatiokertoimen \(r_{y;x_1,...,x_k}\) neliö. Yhteiskorrelaatiokerroin on selitettävän muuttujan \(y_i\) ja sen sovitteen \(\hat y_i\) välinen korrelaatiokerroin.
2.2 Testaus
Samoin kuin yhden selittäjän tapauksessa, on syytä testata, onko selitettävän ja selittäjien välillä todellista lineaarista yhteyttä. Kun selittäjiä on useita, voidaan tehdä monenlaisia testejä.
Tärkeintä on testata aluksi, onko mikään selittäjä merkitsevä eli poikkeaako mikään regressiokertoimista \(\beta_1, ..., \beta_k\) nollasta. Tällöin nollahypoteesina on \(H_0: \ \beta_1 = \beta_2 =...=\beta_k = 0\) eli että kaikki regressiokertoimet ovat yhtäsuuria kuin 0. Kun hypoteesi on tosi, F-testisuure \[ F=\frac{R^2/k}{(1-R^2)/(n-k-1)}\sim F(k,n-k-1) \] noudattaa F-jakaumaa vapausasteilla \(n\) ja \(n-k-1\). Tilasto-ohjelmat yleensä tulostavat oletusarvoisesti tämän testisuureen arvon ja siihen liittyvän p-arvon. Nollahypoteesi voidaan hylätä riskitasolla \(100\alpha\ \%\), jos \(F>F_{1-\alpha;k,n-k}\), missä kriittinen arvo \(F_{1-\alpha;k,n-k}\) on F-jakauman kvantiilifunktion (kertymäfunktion käänteisfunktion) arvo pisteessä \(1-\alpha\).
Toisessa testityypissä voidaan testata yksittäisten regressiokerrointen merkitsevyyttä. Tämä voidaan tehdä samalla tavoin kuin yhden selittäjän tapauksessa t-testin avulla. Jos hypoteesi \(H_0:\ \beta_i=\beta_{i0}\) on tosi, testisuure \[ t= \frac{\hat \beta_i -\beta_{i0}}{s_{\hat \beta_i}} \sim t(n-k-1) \] noudattaa \(t\)-jakaumaa \(n-k-1\) vapausasteella. Tilasto-ohjelmat tulostavat oletusarvoisesti hypoteesia \(H_0:\ \beta_i=0\) vastaavan testisuureen arvon sekä sitä vastaavan kaksipuoleisen testin p-arvon.
Huomaa, että jos selittäjiä on vain yksi, kaksipuoleinen t-testi ja kaikkien selittäjien merkitsevyyttä testaava F-testi johtavat samaan lopputulokseen. Itse asiassa tällöin F-testisuureen arvo on t-testisuureen neliö ja myös p-arvot ovat samat.
Kolmannessa testityypissä testataan, onko jokin selittäjien osajoukko tilastollisesti merkitsevä. Jos testataan \(d\) viimeistä selittäjää, nollahypoteesi on \(H_0:\ \beta_{k_0+1}=...=\beta_{k}=0\), missä \(k_0 = k-d\). Kun \(H_0\) on voimassa, regressiomalli kutistuu muotoon \[ Y=\beta_0 +\beta_1 x_1 +...+\beta_{k_0} x_{k_0}+\epsilon. \] Tätäkin voidaan testata F-testillä. Kun \(H_0\) on voimassa, testisuure on \[\begin{equation} \frac{(R^2-R_0^2)/d}{(1-R^2)/(n-k-1)}\sim F(d,n-k-1), \tag{2.1} \end{equation}\] missä \(R_0\) on nollahypoteesia vastaava selitysaste. Jos tällaisen testin haluaa tehdä jollain tilasto-ohjelmalla, on yleensä sovitettava erikseen alkuperäinen malli ja sen osamalli.
Esim. Tutkitaan, mitkä tekijät voivat selittää onnellisuutta. Aineisto (Data for Table 2.1) liittyy Maailman onnellisuusraporttiin (Helliwell et al. 2023). Käytetään vuoden 2019 havaintoja. Alkuperäisessä raportissa tehdyssä regressioanalyysissä on yhdistetty eri vuosien havainnot. Aineistossa on muuttujat:
| Muuttuja | Selite |
|---|---|
| maa | maa |
| onni | onnellisuusindeksi (välillä 0–10) |
| bkt_pc | log(BKT / asukasluku) |
| sos_tuki | sosiaalinen tuki (välillä 0–1) |
| terv_aika | terveen elinajan odote syntyessä |
| valinnanvapaus | vapaus tehdä elämänvalintoja (välillä 0–1) |
| anteliaisuus | halukkuus lahjoittaa hyväntekeväisyyteen (suhteessa muuttujaan bkt_pc) |
| lahjonta | käsitykset lahjonnan yleisyydestä (välillä 0–1) |
onni <- read.table("../datat/onnellisuus.csv", sep = ",", header = TRUE)
onni <- onni[onni$year == 2019 , c(1, 3:9)]
onni <- na.omit(onni) # poistetaan rivit, joilla puuttuvia arvoja
colnames(onni) <- c("maa", "onni","bkt_pc", "sos_tuki", "terv_aika",
"valinnanvapaus", "anteliaisuus", "lahjonta")
malli1 <- lm(onni ~ . - maa, data = onni) # käytetään kaikkia selittäjiä paitsi maata
summary(malli1)
##
## Call:
## lm(formula = onni ~ . - maa, data = onni)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.50768 -0.30288 0.08641 0.37756 1.23469
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -2.66812 0.73024 -3.654 0.000382 ***
## bkt_pc 0.11585 0.08528 1.359 0.176793
## sos_tuki 3.05486 0.61506 4.967 2.24e-06 ***
## terv_aika 0.05903 0.01460 4.042 9.32e-05 ***
## valinnanvapaus 1.78915 0.51832 3.452 0.000766 ***
## anteliaisuus 0.30946 0.36593 0.846 0.399388
## lahjonta -0.75001 0.32330 -2.320 0.022011 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.5743 on 122 degrees of freedom
## Multiple R-squared: 0.752, Adjusted R-squared: 0.7398
## F-statistic: 61.66 on 6 and 122 DF, p-value: < 2.2e-16F-testisuureen perusteella nollahypoteesi, jonka mukaan kaikki regressiokertoimet ovat nollia (\(H_0:\ \beta_1=....=\beta_6=0\)), voidaan hylätä. Testin kriittinen arvo 5 % riskitasolla on 2.1737327 (R:llä qf(0.95, 6, 122)) ja testisuureen arvo 61.66 ylittää tämän reilusti. Saman tuloksen näkee myös p-arvosta, joka on laskentatarkkuuden rajoissa nolla.
Yksittäisten selittäjien merkitsevyyttä voidaan tutkia t-testeillä. Kaksipuoleisessa testauksessa kriittinen arvo on 1.9795999 (R:llä qt(0.975, 122)). Muuttujilla sos_tuki, terv_aika, valinnanvapaus ja lahjonta t-testisuureen itseisarvo ylittää kriittisen arvon, joten nämä muuttujat ovat tilastollisesti merkitseviä selittäjiä.
Tutkitaan vielä, voidaanko muuttujat bkt_pc ja anteliaisuus pudottaa mallista pois. Toisin sanoen testataan hypoteesia \(H_0:\ \beta_1=\beta_5=0\). Sitä varten estimoidaan malli ilman näitä muuttujia. F-testi voitaisiin tehdä laskemalla testisuure selitysasteiden avulla kaavan (2.1) mukaisesti, mutta R:ssä testin voi tehdä helposti funktion anova avulla.
malli0 <- lm(onni ~ sos_tuki + terv_aika + valinnanvapaus + lahjonta, data = onni)
anova(malli0, malli1)
## Analysis of Variance Table
##
## Model 1: onni ~ sos_tuki + terv_aika + valinnanvapaus + lahjonta
## Model 2: onni ~ (maa + bkt_pc + sos_tuki + terv_aika + valinnanvapaus +
## anteliaisuus + lahjonta) - maa
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 124 40.932
## 2 122 40.243 2 0.68858 1.0437 0.3553Nollahypoteesia ei hylätä, joten suppeampi malli on riittävä. Katsotaan vielä siihen liittyvät tulokset:
summary(malli0)
##
## Call:
## lm(formula = onni ~ sos_tuki + terv_aika + valinnanvapaus + lahjonta,
## data = onni)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.55722 -0.30468 0.08638 0.38679 1.28695
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -2.53313 0.71567 -3.540 0.000565 ***
## sos_tuki 3.34910 0.57176 5.858 3.96e-08 ***
## terv_aika 0.07046 0.01120 6.293 4.89e-09 ***
## valinnanvapaus 1.87062 0.51246 3.650 0.000385 ***
## lahjonta -0.87248 0.30915 -2.822 0.005557 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.5745 on 124 degrees of freedom
## Multiple R-squared: 0.7478, Adjusted R-squared: 0.7396
## F-statistic: 91.9 on 4 and 124 DF, p-value: < 2.2e-16Sovitettu malli voidaan esittää muodossa \[\begin{eqnarray*} \mbox{onni}&=& -2.53 + 3.35\cdot \mbox{sos tuki} + 0.0705 \cdot \mbox{terv aika}+ 1.87\cdot \mbox{valinnanvapaus}\\ &&- 0.872\cdot \mbox{lahjonta}\ (+\ \mbox{jäännös}). \end{eqnarray*}\] Mallia voidaan tulkita seuraavan taulukon mukaisesti:
| Muuttuja | Tulkinta |
|---|---|
| sos_tuki | jos niiden osuus, jotka kokevat saavansa tarvittaessa sosiaalista tukea, kasvaa 0.1:lla (10 %-yksiköllä), onnellisuusindeksi kasvaa 0.335:lla |
| terv_aika | jos terveen elinajan odote kasvaa 10 vuodella, onnellisuusindeksi kasvaa 0.705:lla |
| valinnanvapaus | jos niiden osuus, jotka kokevat saavansa tehdä vapaasti elämänvalintoja, kasvaa 0.1:lla, onnellisuusindeksi kasvaa 0.187:lla |
| lahjonta | jos niiden osuus, jotka kokevat lahjonnan yleiseksi, kasvaa 0.1:lla, onnellisuusindeksi pienenee 0.087:llä |
Mallin selitysaste on \(R^2=0.7478\), joten se selittää noin kolme neljäsosaa onnellisuusindeksin vaihtelusta.
2.3 Jäännöksiin perustuva diagnostiikka
Regressiomallin oletuksien voimassaoloa on syytä tarkastella kriittisesti. Osittain oletukset perustuvat sovellusalueen tuntemukseen ja saattavat vaatia asiantuntijatietoa. Ensinnäkin on mietittävä tulosmuuttujan validiutta: mittaako se haluttua ominaisuutta. Toiseksi on selvitettävä, mitkä muuttujat voisivat selittää tulosmuuttujaa ja yritettävä sisällyttää ne regressiomalliin. Kolmanneksi on harkittava edustavuutta: voiko otoksesta estimoitua regressiomallia yleistää tapauksiin, johon sitä haluttaisiin soveltaa. (Gelman and Hill 2007)
Seuraavia oletuksia on mahdollista tutkia tilastollisesti, esimerkiksi jäännöstarkastelujen avulla:
Lineaarisuus ja additiivisuus. Lineaarisessa regressiomallissa mallin systemaattinen osa on selittäjien lineaarikombinaatio (\(Y=\beta_0+\beta_1 x_1 +\beta_2 x_2 +...\)). Jos selitettävän ja selitettävien suhdetta kuvaa paremmin tulo \(Y=\alpha_0x_1^{\beta_1}x_2^{\beta_2}...\), logaritmointi voi muuntaa mallin additiiviseksi: \(\log(Y)=\log(\alpha_0)+\beta_1\log(x_1)+\beta_2\log(x_2)+...\). Jos selitettävä ei riipu lineaarisesti selittäjästä \(x\), sille voi tehdä jonkin muunnoksen, esim. \(1/x\), \(\sqrt{x}\) tai \(\log(x)\). Käyräviivaista riippuvuutta voi usein joustavasti mallintaa ottamalla selittäjiksi sekä \(x\) että \(x^2\).
Virhetermien riippumattomuus. Jos aineistossa on useita havaintoja samasta yksilöstä tai ryhmästä, ne voivat olla keskenään korreloituneita. Ajallisesti peräkkäisillä havainnoilla voi olla autokorrelaatiota. Jos oletus ei pidä paikkaansa, estimaattien keskivirheet ja sen seurauksena p-arvot voivat olla liian pieniä.
Vakiovarianssisuus eli homoskedastisuus. Joskus selitettävän varianssi saattaa vaihdella esim. selitettävän odotusarvon mukaan. Tällöin selitettävän logaritmointi tai muu muunnos voi auttaa. Yksi mahdollisuus on käyttää painotettua PNS-menetelmää. Parametriestimaatit ovat harhattomia mutta eivät kuitenkaan tehokkaita (eli mahdollisimman tarkkoja), jos heteroskedastisuutta (erivarianssisuutta) ei oteta huomioon.
Virhetermin normaalijakautuneisuus. Tämä oletus ei ole yleensä kriittinen. Ainoastaan siinä tapauksessa, että jakauma poikkeaa voimakkaasti normaalisuudesta, tarvitaan toimenpiteitä. Tätä oletusta ei pidä sekoittaa selitettävän muuttujan \(Y\) normaalijakautuneisuuteen.
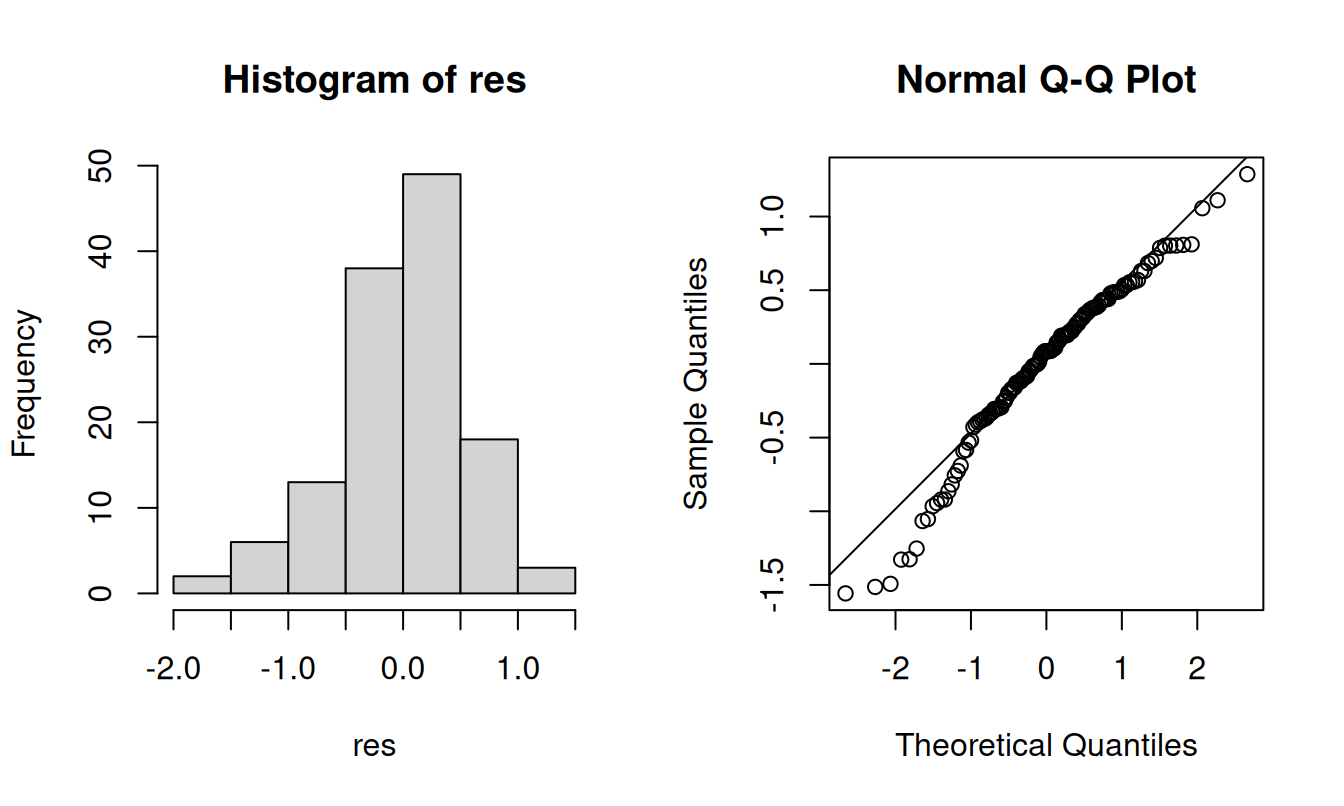
Esim. Tutkitaan edellä sovitetun “onnellisuusmallin” jäännöksiä. Tutkitaan aluksi niiden normaalisuutta histogrammin ja normaalijakaumakuvion avulla. Normaalijakaumakuviossa vaaka-akselilla ovat normaalijakauman järjestystunnuslukujen odotusarvot ja pystyakselilla havainnot kasvavassa järjestyksessä. Jos havainnot (tässä tapauksessa jäännökset) ovat normaalijakautuneita, ne asettuvat kuviossa likimain suoralle.
Alla olevassa kuvioissa on havaittavissa lievää vasemmalle vinoutta mutta ei kuitenkaan niin suurta poikkeavuutta normaalisuudesta, että se olisi ongelma mallin kannalta.
Seuraavaksi on piirretty kaksi jäännösten sirontakuviota; vasemmassa kuviossa jäännökset ovat siinä järjestyksessä kuin ne ovat havaintoaineistossa ja oikeassa ne on piirretty sovitettuja arvoja vastaan. Vasemanpuoleisessa kuviossa ei näy mitään epäsäännöllisyyttä: jäännökset ovat tasaisesti nollan molemmin puolin ja vaihtelu pysyy samanlaisena. Oikeanpuoleisessa varianssi näyttää pienevän oikealle päin mennessä eli kun sovitteet kasvavat. Tästä voisi päätellä, että virhetermin varianssi on pienempi, kun selitettävän odotusarvo on suurempi. Periaatteessa tätä voisi yrittää korjata tekemällä selitettävälle jonkin muunnoksen (esim. potenssimuunnoksen \(Y^\delta\), missä \(\delta >1\)), mutta heteroskedastisuus ei ole kuitenkaan niin suurta, että tämä olisi tarpeellista.
fit <- fitted(malli0)
par(mfrow = c(1,2))
plot(res); abline(h = 0, lty = 3)
plot(res ~ fit); abline(h = 0, lty = 3)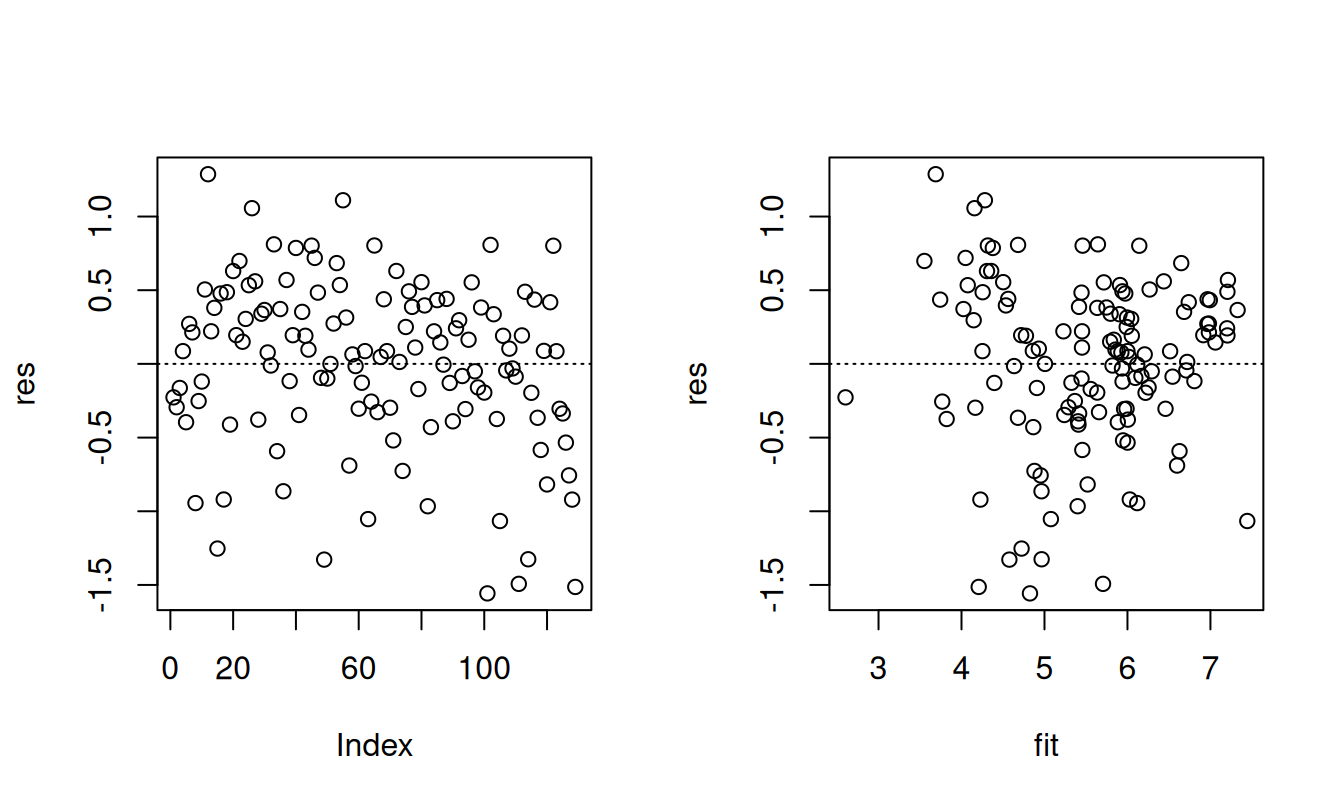
Lopuksi piirrämme vielä jäännökset kaikkia selittäjiä vastaan. Jos jossain kuviossa esiintyisi epäsäännöllisyyttä, tilannetta voisi ehkä korjata tekemällä kyseiselle selittäjälle muuttujanmuunnoksen tai lisäämällä sille toisen asteen termin.
par(mfrow = c(2,2))
plot(res ~ sos_tuki, data = onni); abline(h = 0, lty = 3)
plot(res ~ terv_aika, data = onni); abline(h = 0, lty = 3)
plot(res ~ valinnanvapaus, data = onni); abline(h = 0, lty = 3)
plot(res ~ lahjonta, data = onni); abline(h = 0, lty = 3)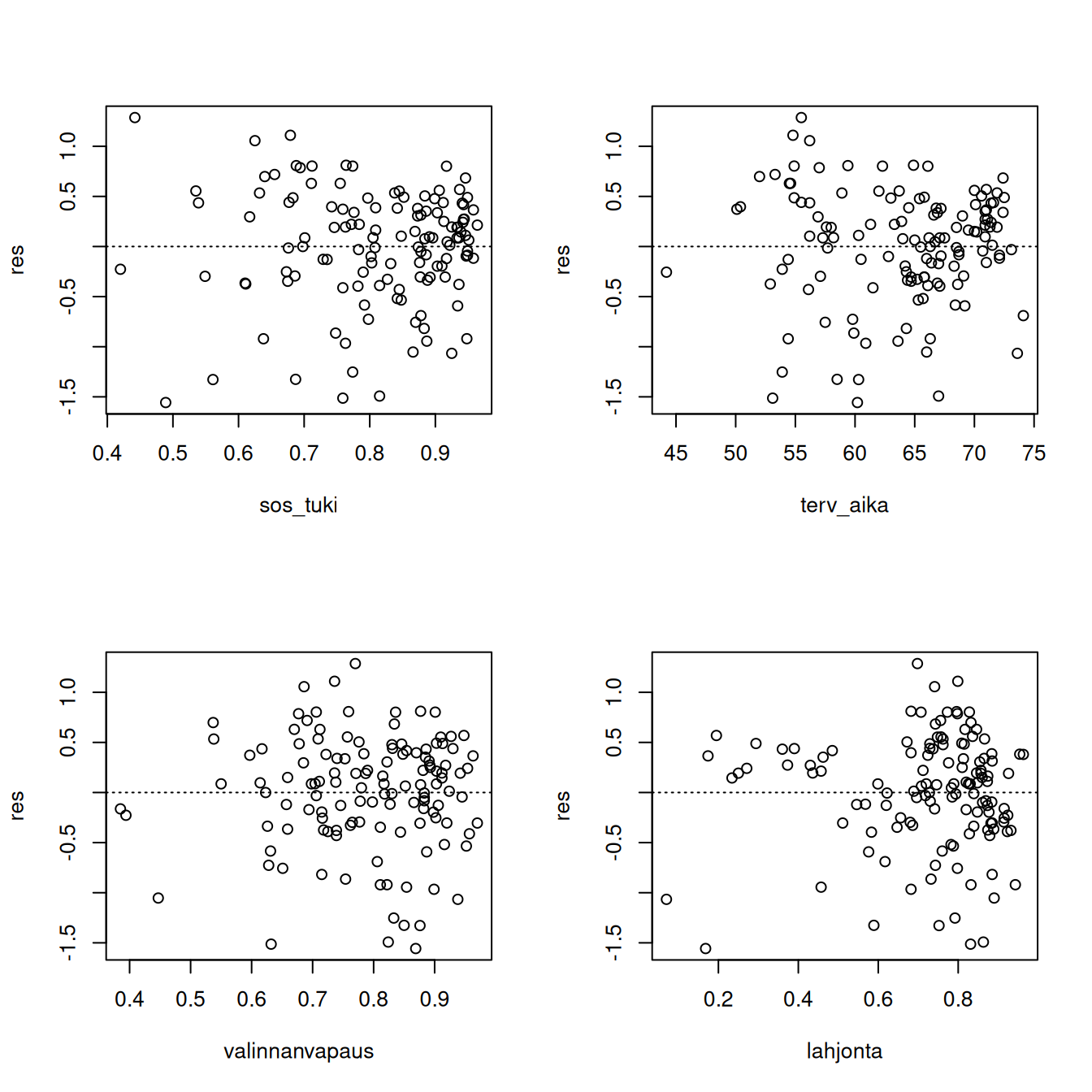
2.4 Regressiomallilla ennustaminen
Regressiomallin yhteydessä ennustamisella voidaan tarkoittaa kahta eri asiaa: 1) tulosmuuttujan uuden arvon tai 2) sen odotusarvon ennustamista. Kummassakin tapauksessa varsinainen ennuste on sama, mutta niihin liittyvät välit ovat erilaiset. Kyseessä ei ole välttämättä tulevaisuuteen kohdistuva ennustaminen vaan tulosmuuttujan arvon arvioiminen, kun selittäjien (ennustimien) arvot tunnetaan.
Tulosmuuttujan uuden arvon \(Y_u\) odotusarvo on \[ \mathrm{E}(Y_u)=\beta_0+\beta_1 x_{u1}+...+\beta_k x_{uk}, \] missä \(x_{u1},...,x_{uk}\) ovat uutta arvoa vastaavat selittäjien arvot. Kun tuntemattomat parametrit \(\beta_j\) korvataan estimaateillaan, saadaan estimaatti tulosmuuttujan odotusarvolle: \[ \hat{\mathrm{E}}(Y_u)=\hat\beta_0+\hat\beta_1 x_{u1}+...+\hat\beta_k x_{uk}, \] Tämän estimaattorin varianssi on muotoa \(\sigma^2 v_u\), missä \(\sigma^2=\mathrm{Var}(\epsilon)\) ja \(v_u\) on uuden havainnon selittäjien \((x_{u1},...,x_{uk})\) ja aineiston selittäjien \((x_{i1},...,x_{ik}),\ i=1,...,n,\) funktio. Yhden selittäjän tapauksessa \[ v_u=\frac1n + \frac{(x_u-\bar x)^2}{\sum_{i=1}^n(x_i-\bar x)^2}. \] \(100(1-\alpha)\%\) luottamusväli uuden havainnon odotusarvolle on \[ \hat{\mathrm{E}}(Y_u)\pm t_{1-\alpha/2;n-k-1}s\sqrt{v_u}. \]
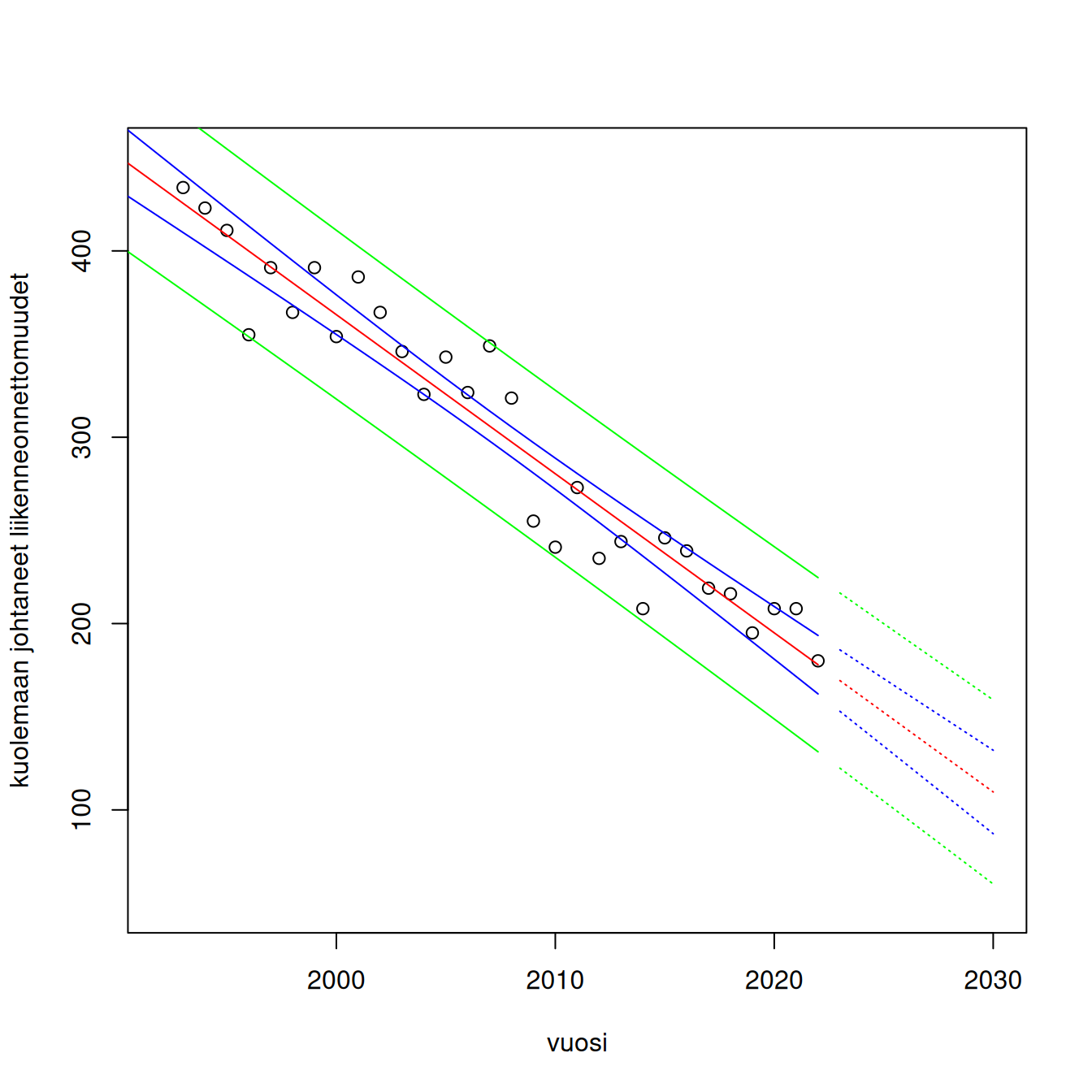
Kun ennustetaan tulosmuuttujan uutta arvoa, täytyy ottaa huomioon uuteen arvoon liittyvä satunnaisuus eli virhetermin \(\epsilon_u\) varianssi. Tämän vuoksi uuden arvon varianssi on, kun otetaan huomioon myös estimointiin liittyvä epävarmuus, on \[\begin{eqnarray*} \mathrm{Var}(Y_u) &=& \mathrm{Var}(\hat \beta_0 + \hat \beta_1 x_{u1}+...+\hat\beta_k x_{uk}+\epsilon_u)\\ &=&\sigma^2v_u +\sigma^2 \\ &=& \sigma^2(v_u+1). \end{eqnarray*}\] Uuden havainnon yhteydessä puhutaan ennustevälistä. Se on \[ \hat{\mathrm{E}}(Y_u)\pm t_{1-\alpha/2;n-k-1}s\sqrt{v_u+1}. \] Esim. Tarkastellaan kuolemaan johtaneiden tieliikenneonnettomuuksien määrää 1931 – 2022. (Lähde: Tilastokeskus)
onn <- read.table("../datat/liikenneonnettomuudet.txt", header = TRUE, skip=2)
colnames(onn) <- c("vuosi", "kuolleet", "loukkaantuneet", "kuol_onn", "loukk_onn")
n <- nrow(onn) # havaintojen lukumäärä
onn$vuosi[n] <- "2022" # Havaintoaineistossa tässä oli "2022*"
onn$vuosi <- as.numeric(onn$vuosi)
plot(kuol_onn ~ vuosi, onn, ylab = "kuolemaan johtaneet liikenneonnettomuudet")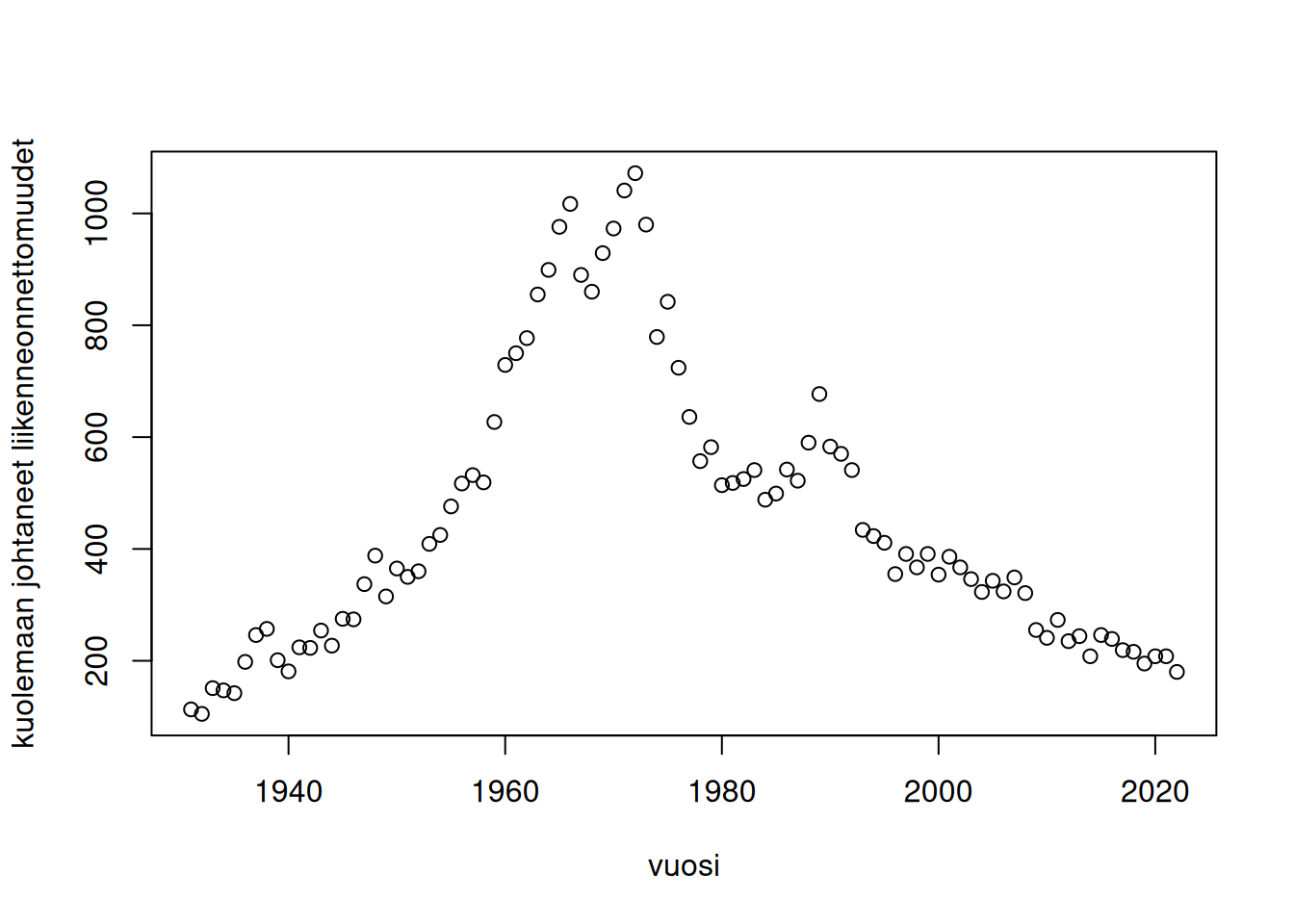
Kuviosta näemme, että onnettomuuksien määrä on vaihdellut suuresti vuosien aikana. Rajoitumme seuraavassa tarkastelemaan vuosia 1992–2022, koska silloin kehitys on ollut tasaista. Sovitamme siihen regressiomallin. Sitten teemme kuvion, jossa näkyy luottamus- että ennusteväli sekä aineiston aikavälille että tulevaisuuteen.
malli <- lm(kuol_onn ~ vuosi, data = subset(onn, vuosi > 1992))
# odotusarvon luottamusväli 1992-2022
luottamus0 <- predict(malli, newdata = onn, interval = "confidence")
plot(kuol_onn ~ vuosi, subset(onn, vuosi > 1992), xlim = c(1992, 2030),
ylim = c(50, 450), ylab = "kuolemaan johtaneet liikenneonnettomuudet")
lines(onn$vuosi, luottamus0[,"fit"], col = "red")
lines(onn$vuosi, luottamus0[,"lwr"], col = "blue")
lines(onn$vuosi, luottamus0[,"upr"], col = "blue")
# ennusteväli 1992-2022
ennuste0 <- predict(malli, newdata = onn, interval = "prediction")
lines(onn$vuosi, ennuste0[,"upr"], col = "green")
lines(onn$vuosi, ennuste0[,"lwr"], col = "green")
# luottamusväli 2023- 2030
uusi <- data.frame(vuosi = 2023:2030)
luottamus <- predict(malli, newdata = uusi, interval = "confidence")
lines(uusi$vuosi, luottamus[,"fit"], col = "red", lty = 3)
lines(uusi$vuosi, luottamus[,"lwr"], col = "blue", lty = 3)
lines(uusi$vuosi, luottamus[,"upr"], col = "blue", lty = 3)
# ennusteväli 2023-2030
ennuste <- predict(malli, newdata = uusi, interval = "prediction")
lines(uusi$vuosi, ennuste[,"lwr"], col = "green", lty = 3)
lines(uusi$vuosi, ennuste[,"upr"], col = "green", lty = 3)