Luku 5 Logistinen regressio
Usein vastemuuttuja on kaksiarvoinen: onnistuminen / epäonnistuminen, sairastuminen / terveenä pysyminen, ostaminen / ostamatta jättäminen. Tilastotieteessä tällaiset kaksiarvoiset (eli dikotomiset) muuttujat on tapana koodata luvuilla 1 ja 0, jolloin ne voidaan ajatella reaalisaatioina Bernoulli-jakautuneesta satunnaismuuttujasta. Kun halutaan selittää vastemuuttujaa \(Y\) muuttujilla \(x_1,...,x_k\), voitaisiin edellisten lukujen tapaan käyttää lineaarista mallia \[ Y=\beta_0+\beta_1 x_1+...+\beta_k x_k +\epsilon. \] Tällä mallilla olisi kuitenkin kaksi vakavaa ongelmaa, kun \(Y\) on dikotominen. Ensinnäkin malli ei rajoita ennusteita tai sovitteita välille (0, 1), vaikka tiedetään, että \(0 < \mathrm{E}(Y) < 1\). Bernoulli-jakautuneen satunnaismuuttujan odotusarvo on yhtä kuin ykkösarvon todennäköisyys: \(\mathrm{E}(Y)=P(Y=1)\). Toiseksi lineaarisen regressiomallin oletus siitä, että virhetermi \(\epsilon\) on normaalijakautunut, ei pidä paikkaansa.
Nämä ongelmat voidaan välttää tekemällä odotusarvolle \(\mathrm{E}(Y)\) muunnos, joka kuvaa sen väliltä \((0,1)\) reaalilukujen joukolle. Malli on tällöin muotoa \[ g(\mathrm{E}(Y))=\beta_0+\beta_1 x_1+...+\beta_k x_k, \] missä \(g()\) on ns. linkkifunktio. Yleisimmin käytetyt linkkifunktiot ovat logit- ja probit-funktiot. Logit-funktio on \[ g(x)=\log\left(\frac{x}{1-x}\right),\ 0 < x < 1, \] ja probit-funktio standardinormaalijakauman kvantiilifunkto (kertymäfunktion käänteisfunktio) \(g(x)=\Phi^{-1}(x)\). Sopivasti skaalattuna logit- ja probit-funktiot eivät paljon poikkea toisistaan, kun \(x\approx 1/2\). Seuraavassa kuviossa on esitetty nämä funktiot sekä lineaarinen approksimaatio kohdassa \(x=1/2\). Jatkossa tyydymme tarkastelemaan logistista regressiota, joka käyttää logit-linkkiä.
curve(log(x / (1 - x)), from = 0, to = 1, ylab = "linkkifunktio g(x)",
xaxp = c(0, 1, 4))
curve(1.6 * qnorm(x), from = 0, to = 1, col = 2, add = TRUE)
curve(4 * (x - 0.5), from = 0, to = 1, col = 3, add = TRUE)
abline(v = seq(0, 1, by = 0.25), lty = 3)
abline(h = seq(-4, 4, by = 2), lty = 3)
legend("topleft", legend = c("logit", "1.6 * probit", "4 * (x - 1/2)"),
col = 1:3, lwd = 1)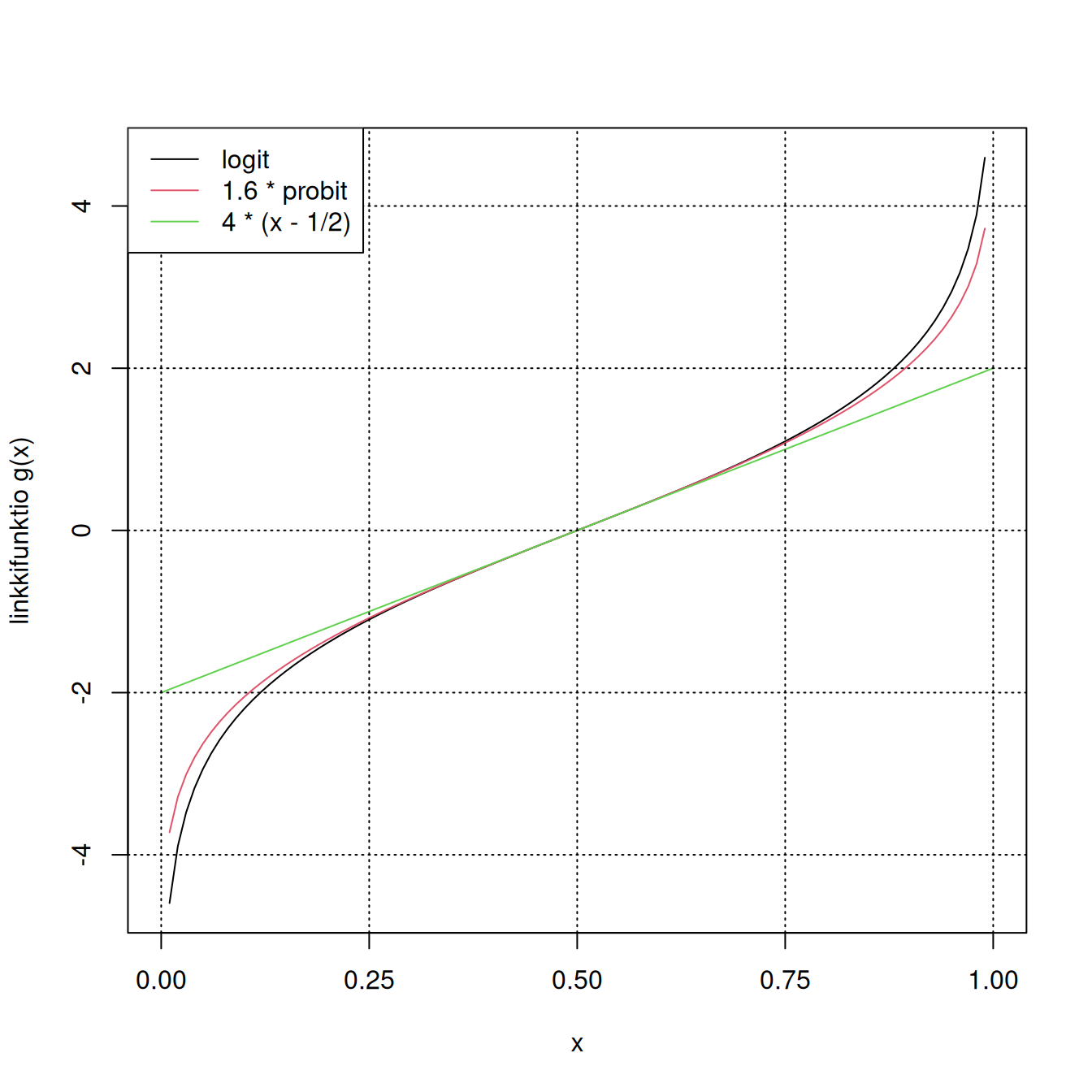
5.1 Estimointi
Yksittäiselle havainnolle \(Y_i\) logistinen regressiomalli voidaan kirjoittaa muodossa \[ \log\left(\frac{p_i}{1-p_i}\right)=\beta_0+\beta_1x_{i1}+...+\beta_k x_{ik}, \] missä \(p_i=P(Y_i=1)=\mathrm{E}(Y_i)\) ja \(x_{i1},...,x_{ik}\) ovat selittäjien arvot. Yhtälöstä voidaan ratkaista todennäköisyys \[\begin{equation} p_i=\frac{\exp(\beta_0+\beta_1x_{i1}+...+\beta_k x_{ik})}{1+\exp(\beta_0+\beta_1x_{i1}+...+\beta_k x_{ik})}. \tag{5.1} \end{equation}\] Parametrien \(\beta_0,...,\beta_k\) estimoinnissa käytetään yleensä suurimman uskottavuuden menetelmää.
Koska havainto \(Y_i\) on Bernoulli-jakautunut, sen todennäköisyysfunktio on \[\begin{eqnarray*} p(y_i;\beta_0,...,\beta_k)&=&P(Y_i=y_i;\beta_0,...,\beta_k)\\ &=&\begin{cases} p_i, & \mbox{ kun } y_i=1,\\ 1-p_i, & \mbox{ kun } y_i=0,\\ \end{cases}\\ &=& p_i^{y_i}(1-p_i)^{1-y_i}. \end{eqnarray*}\] Kun oletetaan havainnot riippumattomiksi, niiden yhteisjakauman todennäköisyysfunktio on tulo \[ p(y_1,...,y_n; \beta_0,...,\beta_k)=\prod_ {i=1}^n p_i^{y_i}(1-p_i)^{1-y_i}. \] Kun tätä ajatellaan tuntemattomien parametrien \(\beta_0,...,\beta_k\) funktiona, kyseessä on uskottavuusfunktio \(L(\beta_0,...,\beta_k)\). Suurimman uskottavuuden menetelmässä määritetään parametrit niin, että ne maksimoivat uskottavuusfunktion. Logistisen regression tapauksessa ei ole suljetun muodon ratkaisukaavaa, mutta ongelma on helppo ratkaista numeerisella optimoinnilla.
5.2 Testaaminen
Logistisen regressiomallin tapauksessa parametrien estimaattoreilla ei ole täsmällisiä jakaumia niin kuin tavallisen lineaarisen mallin tapauksessa. Riittävän suurella otoskoolla jakaumat ovat likimain normaalisia, mitä voidaan käyttää hyväksi testauksessa ja määritettäessä luottamus- ja ennustevälejä. Tilasto-ohjelmat tulostavat yleensä parametriestimaateille keskivirheet ja z-testisuureet p-arvoineen. Kun testattava parametri on nolla, z-testisuure noudattaa likimain standardinormaalijakaumaa.
Yleistetyissä lineaarisissa malleissa, joihin logistinen regressiomalli kuuluu, käytetään testaamisessa neliösummien sijasta deviansseja, jotka perustuvat uskottavuusfunktioon. Samoin kuin neliösummat, devianssit kuvaavat sovitetun mallin poikkeamaa havaintoarvoista. Devianssi on sitä suurempi, mitä huonommin malli sopii aineistoon. R tulostaa ns. nolladevianssin (null deviance), joka mittaa sellaisen mallin sopivuutta, jossa on ainoastaan vakiotermi. Nolladevianssi vastaa lineaarisen mallin kokonaisneliösummaa. Jäännösdevianssi (residual devianssi) mittaa mallin sopivuutta, kun siinä ovat selittäjät mukana. Jäännösdevianssi vastaa lineaarisen mallin jäännösneliösummaa.
Kun testataan hypoteesia \[ H_0:\ \beta_1=\beta_2=...=\beta_k=0, \] voidaan laskea nolladevianssin ja jäännösdevianssin erotus ja verrata sitä \(\chi^2(k)\)-jakauman kriittisiin arvoihin. Kun testataan osaa parametreista, \(H_0:\ \beta_{k_0+1}=...=\beta_{k}=0\), voidaan sovittaa malli ilman näitä parametreja ja niiden kanssa. Kun \(H_0\) on tosi, malleja vastaavien (jäännös)devianssien erotus on likimain \(\chi^2(d)\)-jakautunut, missä \(d=k-k_0\) on testattavien parametrien lukumäärä. R:ssä tämä voidaan tehdä helposti anova-funktiolla käskyllä
anova(malli0, malli1, test = "Chisq")missä malli0 on malli1:n osamalli.
5.3 Tulkintaa
Logistisen regressiomallin kerrointen tulkinta ei ole aivan yhtä helppoa kuin lineaarisessa regressiomallissa. Tulkinta on kuitenkin tärkeä tulosten ymmärtämiseksi.
Parametrien tulkinta liittyy suoraviivaisimmin ns. vetokertoimeen (Peren monisteessa vastasuhde), joka määritellään todennäköisyyksien suhteena \(P(Y=1)/P(Y=0)\). Logistinen regressiomalli antaa vetokertoimen \[ \frac{p}{1-p}=\exp(\beta_0+\beta_1x_1+...+\beta_k x_k). \] Kun selittäjä \(x_j\) kasvaa yhdellä, vetokertoimesta tulee \[ \exp(\beta_0+\beta_1x_1+..+\beta_j(x_j+1)+...+\beta_k x_k)=\exp(\beta_j)\exp(\beta_0+\beta_1x_1+...+\beta_k x_k), \] eli se tulee kerrottua tekijällä \(\exp(\beta_j)\). Uuden ja vanhan vetokertoimen suhdetta, joka siis tässä tapauksessa on \(\exp(\beta_j)\), sanotaan \(vetosuhteeksi\) (tai ristisuhteeksi).
Vetosuhdetta ei ole kovin helppo ymmärtää. Sen sijaan olisi hyödyllistä tietää, miten todennäköisyys \(P(Y=1)\) muuttuu, kun selittäjä \(x_j\) kasvaa yhdellä. Valitettavasti tätä ei voi päätellä suoraan kertoimesta \(\beta_j\), vaan vastaus riippuu lähtöarvosta \(x_j\) sekä muiden selittäjien ja niiden regressiokerrointen arvoista. Jos nämä ovat tiedossa, todennäköisyyden muutos voidaan määrittää kaavan (5.1) avulla. Karkeasti todennäköisyyttä voidaan kuitenkin arvioida logit-funktion lineaarisen arvion perusteella seuraavasti: kun \(x_j\) kasvaa yhdellä, todennäköisyys \(P(Y=1)\) kasvaa enintään luvulla \(\beta_j/4\).
Vetosuhdetta käytetään usein helpommin ymmärrettävän riskisuhteen arvioimiseen. Riskisuhde on \(RS=p_1/p_0\) ja vetosuhde \(VS=[p_1/(1-p_1)]/[p_0/(1-p_0)]\), kun verrataan todennäköisyyttä \(p_1\) todennäköisyyteen \(p_0\). Vetosuhde on likimain yhtäsuuri kuin riskisuhde, \[ \frac{p_1/(1-p_1)}{p_0/(1-p_0)}\approx \frac{p_1}{p_0}, \] kun todennäköisyydet \(p_1\) ja \(p_0\) ovat pieniä (< 0.1).
Esim. Avaruussukkula. Tammikuussa 1986 avaruussukkula Challenger räjähti pian lähdön jälkeen. Kun onnettomuuden syytä tutkittiin, huomio kiinnittyi apuraketin kumisiin O-tiivisteisiin. Alhaisissa lämpötiloissa kumista tulee hauraampi ja vähemmän eristävä. Tutkimuksessa selvisi, että raketin polttoaine pääsi virtaamaan yhden tiivisteen välistä aiheuttaen onnettomuuden.
Laukaisuhetkellä ilman lämpötila oli \(2^{\circ}C\). Olisiko O-tiivisteen pettäminen voitu ennustaa? Ennen onnettomuutta avaruussukkuloilla oli tehty 23 onnistunutta lentoa, ja niissä oli havaittu tiivisteiden vioittumista. Avaruussukkuloissa on kaksi apurakettia, joissa kummassakin kolme tiivistettä. Kultakin lennolta on tiedossa viottuneiden O-tiivisteiden lukumäärä ja lähtöhetken lämpötila. Ks. lisää yksityiskohtia Peren monisteesta ja artikkelista Dalal, Fowlkes, and Hand (1989).
library(faraway)
##
## Attaching package: 'faraway'
## The following object is masked from 'package:daewr':
##
## halfnorm
orings$tempC <- (5/9)*(orings$temp-32) # Muutetaan lämpötila Celsius-asteisiin
plot(damage/6 ~ tempC, data = orings, xlim = c(-5, 30), ylim = c(0,1),
xlab = "Lämpötila (C)", ylab = "Vioittumisen todennäköisyys")
# Sovitetaan logistinen regressiomalli
malli <- glm(cbind(damage, 6-damage) ~ tempC, family = binomial, data = orings)
summary(malli)
##
## Call:
## glm(formula = cbind(damage, 6 - damage) ~ tempC, family = binomial,
## data = orings)
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 4.74351 1.61542 2.936 0.00332 **
## tempC -0.38922 0.09572 -4.066 4.78e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 38.898 on 22 degrees of freedom
## Residual deviance: 16.912 on 21 degrees of freedom
## AIC: 33.675
##
## Number of Fisher Scoring iterations: 6
# Lisätään sovitettu käyrä kuvioon
x <- seq(-5, 30, by = 0.1)
lines(x, plogis(4.74 - 0.389 * x))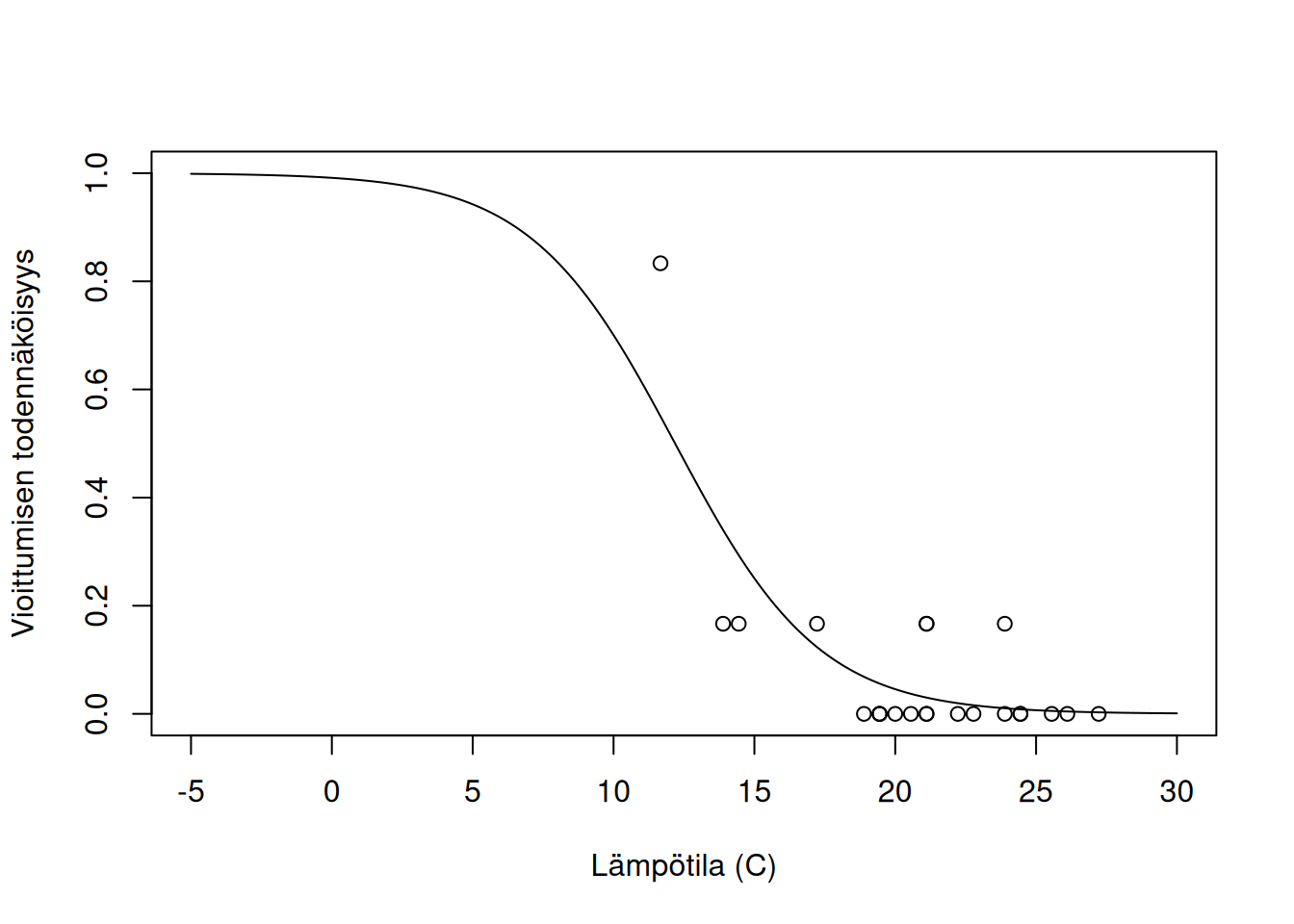
Kuvion pisteet osoittavat vioittuneiden O-tiivisteiden suhteellisen osuuden eri lämpötiloissa aiemmissa 23 avaruussukkuloiden laukaisuissa. Havaintoihin on sovitettu logistinen regressiomalli. Käytettäessä R-ohjelmiston glm-funktiota aineisto voidaan antaa kahdella tavalla: 1) Vastemuuttuja on binäärinen, eli se saa arvoja 0 ja 1. Tällöin se ajatellaan Bernoulli-jakutuneeksi. 2) Aineisto on ryhmitelty niin, että siinä on annettu ykkösten ja nollien lukumäärät kullakin selittäjien arvojen yhdistelmällä. Mallikaavassa “selitettävänä” on kaksisarakkeinen matriisi, jonka ensimmäisellä sarakkeella ovat ykkösten ja toisella sarakkeella nollien lukumäärät. Ykkösten lukumäärä ajatellaan binomijakautuneeksi. (Esimerkkiaineistossa on annettu vioittuneiden O-tiivisteiden lukumäärät kullakin laukaisulla.)
Sovitettu malli on \[ \log\left(\frac{p}{1-p}\right) = 4.74-0.389\cdot x, \] missä \(p\) on O-tiivisteen vioittumisen todennäköisyys ja \(x\) ilman lämpötila avaruussukkulan laukaisuhetkellä. Kun lämpötila kasvaa yhdellä asteella, vioittumisen vetokerroin tulee kerrotuksi luvulla \(\exp(-0.389)\approx 0.678\) eli se pienenee 32.2 %. Siis vioittumisen vetosuhde on 0.678, kun verrataan tiettyä lämpötilaa yhtä astetta alhaisempaan lämpötilaan. Vioittumisen todennäköisyys \(2^{\circ}C\) lämpötilassa voidaan laskea logit-funktion käänteisfunktion, ns. logistisen funktion avulla:
plogis(4.74 - 0.389 * 2)
## [1] 0.9813302(R:n funktio plogis antaa logistisen jakauman kertymäfunktion, joka on siis sama kuin logistinen funktio.)
R:n tulosteesta nähdään myös, että regressiokerroin on tilastollisesti erittäin merkitsevä \((p=4.78\cdot 10^{-5})\). Regressiokertoimen merkitsevyyttä voisi testata myös devianssien avulla. Devianssien erotus on \(38.8981-16.912=21.9861\). Koska testattavia parametreja on 1, erotusta verrataan \(\chi^2(1)\)-jakauman kriittisiin arvoihin. P-arvo on
1 - pchisq(21.9861, df = 1)
## [1] 2.746322e-06joka on vieläkin pienempi kuin käytettäessä z-arvoon perustuvaa testiä.
R tulostaa myös Akaiken informaatiokriteerin arvon. Siitä ei ole yksinään hyötyä, mutta se voi auttaa valitsemaan parhaan ennustemallin, jos verrataan useita malleja. Pienempi kriteerin arvo tarkoittaa parempaa mallia. Tuloksesta nähdään myös, että optimointialgoritmi tarvitsee 6 iteraatiota määrittäessään suurimman uskottavuuden estimaatin.