Luku 6 Parametrittomia menetelmiä
Parametrittomilla (tai epäparametrisilla) tilastollisilla menetelmillä tarkoitetaan määritelmän suppeimmassa mielessä menetelmiä, joissa ei pyritä estimoimaan eikä millään tavoin hyödyntämään populaatioparametreja. Yleensä kuitenkin tätä nimitystä käytetään laaja-alaisemmin viittaamaan menetelmiin, joissa on jollain tavoin löysätty perinteisten menetelmien oletuksia. Tällaisia menetelmiä ovat esim. jakaumasta riippumattomat menetelmät, joissa havaintojen ei oleteta noudattavan jotain tiettyä tilastollista jakaumaa.
Parametrittomien hyötynä on, että niitä voidaan soveltaa tilanteissa, joissa ei ole varmuutta perinteisten menetelmien vaatimien oletusten paikkansapitävyydestä. Haittapuolena on, että tulokset ovat usein heikompia kuin vahvempiin oletuksiin perustuvat menetelmät, esim. menetelmät, joissa oletetaan havaintojen normaalijakautuneisuus. Parametrittomat menetelmät ovat usein vakaita (robusteja), mikä tarkoittaa sitä, että niiden antamat tulokset eivät ole herkkiä mallioletuksille tai vierashavainnoille. Toisaalta parametrisetkin menetelmät voivat olla melko vakaita. Esim. havaintojen normaalijakautuneisuuteen perustuva odotusarvon luottamusväli on melko vakaa, sillä keskiarvon jakauma voi olla lähes normaalinen, vaikka yksittäiset arvot eivät olisi.
6.1 Merkkitesti
Merkkitestissä testataan, onko populaatiojakaumalla jokin tietty mediaani. Siinä ei tarvitse olettaa mitään itse jakaumasta tai sen muodosta, joten se on jakaumasta riippumaton menetelmä. Tiukasti tulkiten se ei ole parametriton menetelmä, koska mediaani on jakaumaa tai populaatiota kuvaileva parametri.
Testissä oletetaan, että havainnot \(X_1,...,X_n\) ovat riippumattomia ja peräisin jakaumista, joiden mediaani on \(m\). Yleensä havainnot oletetaan samoin jakautuneiksi, mutta tämä ei ole välttämätöntä merkkitestin yhteydessä. Testin nollahypoteesina on, että mediaanilla on jokin tietty arvo: \(H_0:\ m=m_0.\) Testisuure \(S\) on niiden havaintojen lukumäärä, jotka ovat suurempia kuin \(m_0\). Tämä on sama kuin niiden erotusten \(X_j-m_0\) lukumäärä, joilla on plus-merkki (eli jotka ovat positiivisia), mistä tulee nimitys merkkitesti. Jos yksi tai useampi havainto on täsmälleen yhtäsuuri kuin \(m_0\), nämä havainnot on tapana tiputtaa pois ennen testaamista.
Kun \(H_0\) on tosi, \(P(X_j>m_0)=\frac12,\ j=1,...,n\), mistä seuraa, että \(S\sim Bin(n,\frac12)\). Tässä on mahdollista tehdä täsmällinen binomijakauman todennäköisyyksiin perustuva testi, mutta kun \(n\) on riittävän suuri (>20), voidaan käyttää normaalijakauma-approksimaatiota \[ S \overset{a}{\sim} N(\frac{n}{2},\frac {n}{4}). \] Nollahypoteesin vallitessa standardoitu testisuure \(Z=2\sqrt{n}(S/n-1/2)\) noudattaa likimain standardinormaalijakaumaa.
Esim. Osakkeiden hintojen suhteelliset muutokset eli tuotot ovat korreloimattomia, mikäli hypoteesi markkinoiden tehokkuudesta pitää paikkaansa. Yleensä tarkastellaan ns. log-tuottoja, jotka ovat logaritmoitujen hintojen muutoksia ja jotka ovat likimain yhtäsuuria suhteellisten muutosten kanssa lyhyellä aikavälillä. Niiden jakauma on yleensä paksuhäntäisempi kuin normaalijakauma. Tarkastellaan seuraavassa osakeindeksiä OMXH25, joka koostuu Helsingin pörssin 25 vaihdetuimmasta osakkeesta.
library(tseries)
# Haetaan dataa Yahoon palvelusta
OMXH25 <- get.hist.quote("^omxh25", quote = "Close")## time series starts 2013-03-05
## time series ends 2026-02-11
tuotot <- 100 * diff(log(OMXH25)) # Tarkastellaan päivittäisiä prosenttimuutoksia
par(mfrow = c(1,2))
hist(tuotot); qqnorm(tuotot); qqline(tuotot)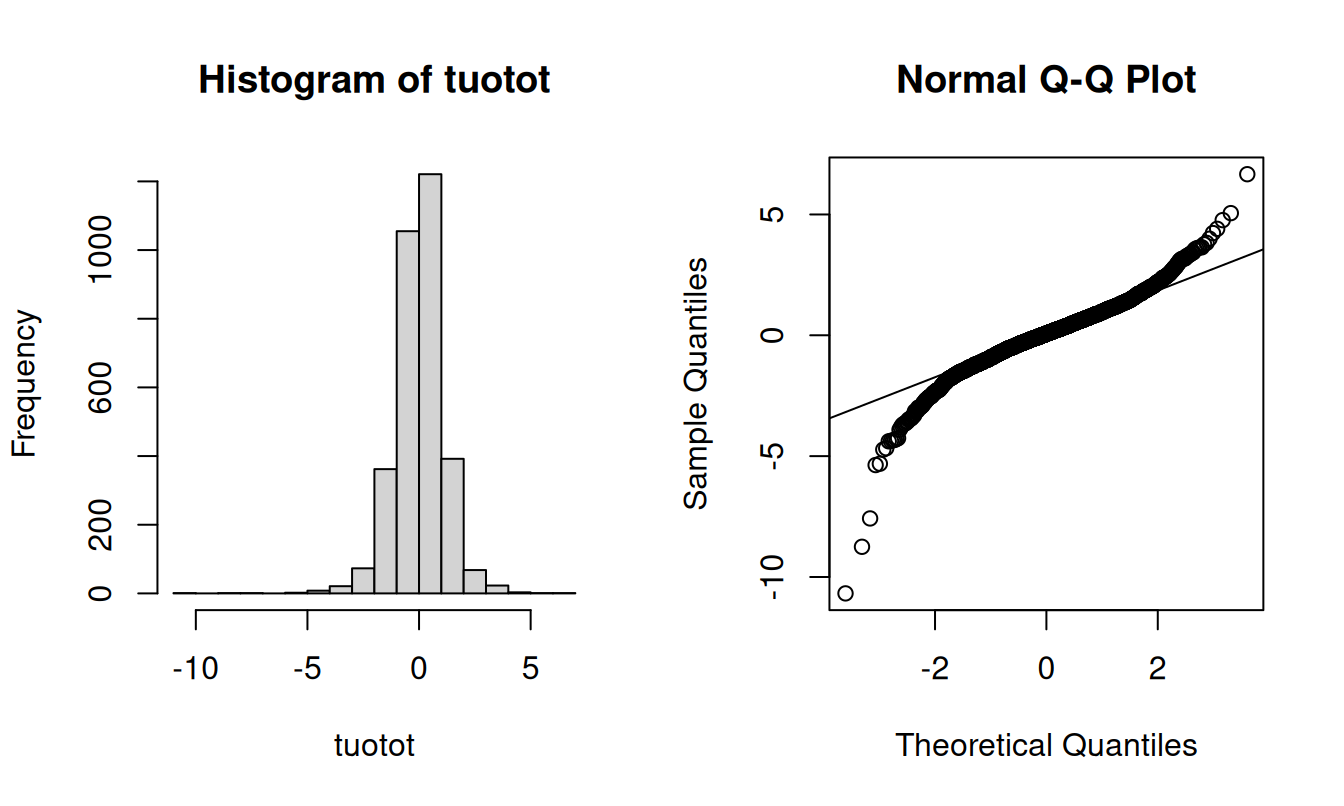
Testataan seuraavaksi merkkitestillä, onko tuottojakauman mediaani nolla.
# Tarkka binomijakaumaan perustuva testi
# Seuraavassa sum(tuotot > 0) antaa nollaa suurempien havaintojen lukumäärän
# ja sum(tuotot != 0) nollasta poikkeavien havaintojen lukumäärän
binom.test(sum(tuotot > 0), sum(tuotot != 0))
##
## Exact binomial test
##
## data: sum(tuotot > 0) and sum(tuotot != 0)
## number of successes = 1709, number of trials = 3228, p-value =
## 0.0008765
## alternative hypothesis: true probability of success is not equal to 0.5
## 95 percent confidence interval:
## 0.5120364 0.5467702
## sample estimates:
## probability of success
## 0.52943
# Normaalijakauma-arvioon perustuva testi
# Z-testisuureen arvo
z <- 2 * sqrt(sum(tuotot != 0)) * (mean(tuotot > 0) - 0.5)
z
## [1] 3.251118
# Kaksipuoleisen testin p-arvo
2 * (1 - pnorm(z))
## [1] 0.00114952
# Siis hylätään nollahypoteesi, ja päätellään että tuottojakauman mediaani
# on > 0.6.2 Wilcoxonin merkkisijatesti
Tavallinen merkkitesti ei hyödynnä maksimaalisesti havaintojen antamaa informaatiota. Siinä kunkin havainnon kohdalla tarkastellaan ainoastaan, onko se suurempi vai pienempi kuin nollahypoteesia vastaava mediaani \(m_0\). Vaihtoehtoinen Wilcoxonin merkkisijatesti ottaa huomioon myös havaintojen sijaluvut. Testissä riittää olettaa, että tarkasteltava tilastomuuttuja on järjestysasteikollinen. Oletetaan, että havainnot \(X_1,X_2,...,X_n\) ovat riippumattomia ja peräisin symmetrisestä jakaumasta, jonka mediaani on \(m\). Nollahypoteesina on, että mediaanilla on jokin tietty arvo: \(H_0:\ m=m_0.\)
Testissä lasketaan havaintojen etäisyydet \(m_0\):sta, \(|X_1-m_0|,...,|X_n-m_0|\), ja annetaan näille sijaluvut 1,..,n niin, että pienin etäisyys saa arvon 1, toiseksi pienin arvon 2, jne. Kukin sijaluku saa miinusmerkin, jos \(X_j < m_0\), ja plusmerkin, jos \(X_j > m_0\). Testisuure \(W\) on niiden sijalukujen summa, joilla on miinusmerkki, eli siis niiden, joilla \(X_j < m_0\). (Yhtäpitävästi voitaisiin käyttää niiden sijalukujen summaa, joilla on plusmerkki.) Yhteenlaskettavat sijaluvut voidaan valita \(2^n\) eri tavalla, sillä kukin sijaluku voi saada joko miinus- tai plusmerkin. Kaikki nämä valinnat ovat yhtä todennäköisiä nollahypoteesin vallitessa, sillä jakauman symmetrisyyden vuoksi erotus \(X_j-m_0\) ja sen vastaluku ovat yhtä todennäköisiä. Tämän perusteella voidaan määrittää testisuureen jakauma.
Esim. Tarkastellaan resistanssimittauksia kymmenen \(100\ \Omega\) vastuksen erästä, \[ 99.7\ \ 99.9\ \ 100.4\ \ 100.6\ \ 100.7\ \ 101.1\ \ 101.3\ \ 101.6\ \ 102.1\ \ 102.3 \] Testattaessa hypoteesia \(H_0:\ m=100\), erotukset \(X_j-m_0\) ovat \[ -0.3\ \ -0.1\ \ 0.4\ \ 0.6\ \ 0.7\ \ 1.1\ \ 1.3\ \ 1.6\ \ 2.1\ \ 2.3 \] ja etäisyyksien \(|X_j-m_0|\) sijaluvut \[ 2\ \ 1\ \ 3\ \ 4\ \ 5\ \ 6\ \ 7\ \ 8\ \ 9\ \ 10. \] Nyt testisuure on niiden sijalukujen summa, joilla on negatiivinen merkki, siis \(W=2+1=3\). Nyt \(\Pr(W\le 3|H_0)=5/2^{10}=0.0049\), sillä on 5 tapaa valita yhteenlaskettavat sijaluvut niin, että \(W \le 3\). Tämä on yksipuoleista hypoteesia \(H_1:\ m>100\) vastaava p-arvo. Kaksipuoleisen hypoteesin \(H_1:\ m\neq 100\) p-arvo saadaan kertomalla tämä kahdella.
Tehdään tämä vielä R:llä:
x <- c(99.7, 99.9, 100.4, 100.6, 100.7, 101.1, 101.3, 101.6, 102.1, 102.3)
wilcox.test(x, mu = 100, alternative = "greater")
##
## Wilcoxon signed rank exact test
##
## data: x
## V = 52, p-value = 0.004883
## alternative hypothesis: true location is greater than 100Huomaa, että R käyttää testisuureena plusmerkkisten sijalukujen summaa, joka on \(10\cdot11/2-3=52\).
Suurella otoskoolla voidaan käyttää normaalijakauma-arviota: \[ Z=\frac{W-n(n+1)/4}{\sqrt{n(n+1)(2n+1)/24}} \] noudattaa likimain standardinormaalijakaumaa.
Sekä merkkitestiä että merkkisijatestiä voidaan pitää yhden otoksen t-testin epäparametrisena versiona. Useimmiten käytännössä näitä testejä käytetään ns. vastinparitilanteessa, jossa kukin koeyksikkö/yksilö mitataan ennen ja jälkeen käsittelyn/hoidon, lasketaan mittausten erotus, ja testataan, poikkeaako erotusmuuttujan keskiluku nollasta. Yhden otoksen testien perusteella voidaan myös johtaa luottamusvälejä: ne keskiluvut \(m_0\), joita vastaavaa hypoteesia ei hylätä kaksipuoleisessa testissä, muodostavat luottamusvälin.
6.3 Wilcoxonin sijasummatesti
Testattaessa, ovatko riippumattomat otokset samasta jakaumasta, voidaan käyttää t-testejä. Epäparametrinen vastine on Wilcoxonin sijasummatesti (eli Mannin-Whitneyn U-testi). Siinä ei tarvitse olettaa havaintojen normaalijakautuneisuutta, ja ne voivat olla järjestysasteikollisia.
Tarkastellaan kahta riippumatonta satunnaisotosta \(X_{11},...,X_{1n_1}\) ja \(X_{21},...,X_{2n_2}\). Testataan nollahypoteesia, että molempien otosten havainnot ovat peräisin samasta jakaumasta. Vaihtoehtoisissa hypoteeseissa oletetaan, että jakaumat ovat muuten samat mutta niilä on eri sijaintiparametrit, siis \(F_2(x)=F_1(x+\delta)\). (Testi voidaan myös määritellä yleisemmin niin, että vaihtoehtoinen hypoteesi kattaa kaikki tapaukset, joissa jakaumat poikkeavat toisistaan. Tällöin testi on kuitenkin tarkentuva ainoastaan, jos vaihtoehtoisen hypoteesin vallitessa \(P(X_1>X_2)\neq P(X_2>X_1)\), missä \(X_1\) on ensimmäisen ja \(X_2\) toisen otoksen havainto.)
Testisuure lasketaan niin, että molempien otosten havainnot yhdistetään, asetetaan suuruusjärjestykseen, niille annetaan sijaluvut ja lopuksi ensimmäistä otosta vastaavat sijaluvut lasketaan yhteen. (Huom. R vähentää tästä summasta vielä ensimmäisen otoksen sijalukujen summan minimiarvon \(n_1(n_1+1)/2\)). Nollahypoteesin vallitessa sijaluvut ovat tasaisesti sekoittuneet, minkä perusteella voidaan määrittää testisuureen jakauma. Sijaluvut ovat siis \(1,2,...,n_1+n_2\), ja \(n_1\) yhteenlaskettavaa sijalukua voidaan valita \(\binom{n_1+n_2}{n_1}\) tavalla.
Esimerkki. Verrataan kahta geologista muodostumaa mineraalisisällön suhteen. Tätä varten ensimmäisestä muodostumasta poimitaan 7 malminäytettä ja toisesta 5. Kemiallisen analyysin perusteella saadaan seuraavat mittausarvot:
| Muodostelma 1 | 7.7 | 11.1 | 6.8 | 9.8 | 4.9 | 6.1 | 15.1 |
| Muodostelma 2 | 4.7 | 6.4 | 4.1 | 3.7 | 3.9 |
Yhdistetty otos sijalukuineen on
| Yhdistetty otos | 3.7 | 3.9 | 4.1 | 4.7 | 4.9 | 6.1 | 6.4 | 6.8 | 7.6 | 9.8 | 11.1 | 15.1 |
| Sijaluvut | 1* | 2* | 3* | 4* | 5 | 6 | 7* | 8 | 9 | 10 | 11 | 12 |
Laskujen helpottamiseksi valitaan ‘ensimmäiseksi otokseksi’ jälkimmäinen, pienempi otos. Sitä vastaavat sijaluvut on taulukossa merkitty tähdellä ja niiden summa on \(W=1+2+3+4+7=17\). Kun tästä vähennetään minimiarvo \(5\cdot 6/2=15\) saadaan R:n versio testisuureesta. Testin perusteella nollahypoteesi hylätään 5 % riskitasolla, kun vaihtoehtoinen hypoteesi on, että jakaumien sijaintiparametrit ovat erisuuret.
x1 <- c(4.7, 6.4, 4.1, 3.7, 3.9)
x2 <- c(7.7, 11.1, 6.8, 9.8, 4.9, 6.1, 15.1)
wilcox.test(x1, x2, alternative = "two.sided")
##
## Wilcoxon rank sum exact test
##
## data: x1 and x2
## W = 2, p-value = 0.0101
## alternative hypothesis: true location shift is not equal to 0Myös tämän testin tapauksessa voidaan käyttää normaalijakauma-arviota: \[ Z = \frac{W-n_1(n_1+n_2+1)/2}{\sqrt{n_1n_2(n_1+n_2+1)/12}}, \] joka on likimain \(N(0,1)\)-jakautunut \(H_0\):n vallitessa.
6.4 Empiirinen kertymäfunktio
Tilastollisten jakaumien parametrittomia estimaatteja ovat histogrammi ja empiirinen kertymäfunktio. Olkoot \(X_j,\ j=1,...,n\) satunnaisotos jakaumasta, jonka kertymäfunktio on \(F(x)\). Empiirinen kertymäfunktio (otoskertymäfunktio) \(\hat F(x)\) määritellään niiden suhteellisena osuutena, jotka ovat enintään \(x\):n suuruisia: \[ \hat F(x)=\frac1{n}\sum_{i=1}^nI_{(-\infty,x]}(X_j), \] missä \(I_{(-\infty,x] }(u)\) on osoitinfunktio sille, että \(u\le x\) (eli se saa arvon 1, kun \(u\le x\), ja 0, muuten).
Tarkastellaan seuraavaksi, millainen estimaattori empiirinen kertymäfunktio on todelliselle kertymäfunktiolle \(F(x)=P(X\le x)\). Olkoon \(Y=n\hat F(x)\) niiden havaintojen lukumäärä, jotka ovat pienempiä tai yhtäsuuria kuin \(x\). Koska havainnot ovat riippumattomia, \(Y\sim Bin(n,F(x))\). Binomijakauman ominaisuuksista seuraa, että \(\mathrm{E}(Y)=nF(x)\) ja \(\mathrm{Var}(Y)=nF(x)(1-F(x))\). Edelleen, koska \(\hat F(x)=Y/n\), saamme empiirisen kertymäfunktion odotusarvon ja varianssin pisteessä \(x\): \[ \mathrm{E}\ \hat F(x)=F(x), \quad \mathrm{Var}\ \hat F(x) =\frac{F(x)(1-F(x))}{n}. \] \(\hat F(x)\) on siis harhaton estimaattori kertymäfunktiolle \(F(x)\) pisteessä \(x\), ja sen varianssi lähestyy nollaa, kun otoskoko kasvaa kohti ääretöntä.
Keskeisen raja-arvolauseen perusteella \(\hat F(x)\) on likimain normaalijakautunut riittävän suurella otoskoolla. Tämän perusteella voidaan muodostaa kertymäfunktiolle luottamusvyö. Tason \(100(1-\alpha)\ \%\) luottamusvyö on
\[
\hat F(x)\pm z_{1-\alpha/2}\sqrt{\frac{\hat F(x)(1-\hat F(x))}{n}}.
\]
Tämä on ns. pisteittäinen luottamusvyö, sillä kussakin yksittäisessä pisteessä \(x\) kaavan määrittelemä luottamusväli sisältää oikean kertymäfunktion arvon \(F(x)\) suunnilleen todennäköisyydellä \(100(1-\alpha)\ \%\).
On myös mahdollista määrittää samanaikainen luottamusvyö, joka sisältää kertymäfunktion samanaikaisesti kaikilla muuttujan \(x\) arvoilla tietyllä todennäköisyydellä. Tämä perustuu Kolmogorovin-Smirnovin testisuureen käyttöön. Se on määritelty jatkuva-arvoiselle satunnaismuuttujalle maksimierona kertymäfunktion ja empiiriisen kertymäfunktion välillä: \[ D_n = \sup_{-\infty < x <\infty}|\hat F(x)-F(x)|. \] Testisuureen jakauman 95 % kvantiili on likimain \[ d_{0.95}=\frac{1.358}{\sqrt{n}+0.12+0.11/\sqrt{n}}. \] Tätä voidaan käyttää sen testaamiseen, että havainnot ovat jakaumasta \(F(x)\), tai samanaikaisen luottamusvälin muodostamiseen. Kolmogorovin-Smirnovin testisuuretta voidaan käyttää myös diskreetin satunnaismuuttujan tapauksessa, mutta silloin luottamusvyö saattaa olla liian leveä.
Kolmogorovin-Smirnovin testisuureesta on myös kahden empiirisen jakauman versio. Sitä voidaan käyttää sen testaamiseen onko kaksi otosta samasta jakaumasta. Testisuure on empiiristen kertymäfunktioiden maksimiero \[ D_{m,n}=\sup_{-\infty < x <\infty}|\hat F(x)-\hat G(x)|, \] missä \(m\) ja \(n\) ovat otoskoot. Sen jakauma vastaa yhden otoksen testisuureen lauseketta, kun \(n\) korvataan luvulla \(mn/(m+n)\).
Esim. Tarkastellaan vuoden 2023 osaketuottoja käyttäen indeksejä OMXH25 ja OMXC25 (Kööpenhaminan indeksi).
OMXH25 <- get.hist.quote("^omxh25", quote = "Close", start = "2023-01-01", end = "2023-12-12",
quiet = TRUE)
OMXC25 <- get.hist.quote("^omxc25", quote = "Close", start = "2023-01-01", end = "2023-12-12",
quiet = TRUE)
tuototH <- 100 * diff(log(as.vector(OMXH25)))
tuototC <- 100 * diff(log(as.vector(OMXC25)))
par(mfrow = c(1,2))
# Vasemmanpuoleinen kuvio
n <- length(tuototH)
plot.ecdf(tuototH, do.points = FALSE, main = "")
plot.ecdf(tuototC, add = TRUE, col = "red", do.points = FALSE)
# Määritetään pisteittäinen luottamusvyö
Fn <- 0:n / n
leveys <- 1.96 * sqrt(Fn * (1 - Fn) / n)
ala <- pmax(0, Fn - leveys)
ylä <- pmin(1, Fn + leveys)
# Määritetään samanaikainen luottamusvyö
D <- 1.358 / (sqrt(n) + 0.12 + 0.11 / sqrt(n))
alaSA <- pmax(0, Fn - D)
yläSA <- pmin(1, Fn + D)
# Oikeanpuoleinen kuvio
plot.ecdf(tuototH, do.points = FALSE, lwd = 2, main = "")
plot(stepfun(sort(tuototH), ala), add = TRUE, do.points = FALSE, col = "green")
plot(stepfun(sort(tuototH), ylä), add = TRUE, do.points = FALSE, col = "green")
plot(stepfun(sort(tuototH), alaSA), add = TRUE, do.points = FALSE, col = "red")
plot(stepfun(sort(tuototH), yläSA), add = TRUE, do.points = FALSE, col = "red") 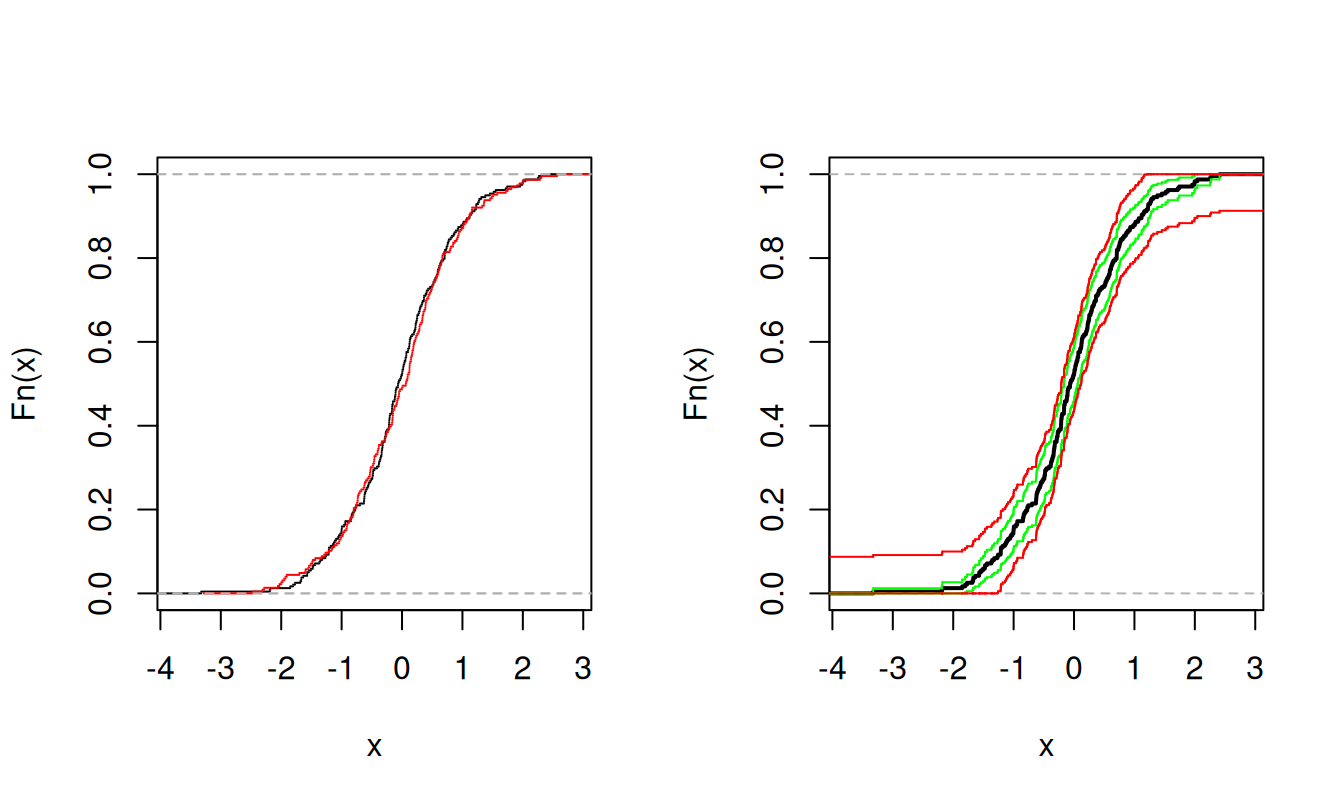
Vasemmanpuoleisessa kuvioissa on Helsingin ja Kööpenhaminan osakeindeksien tuottojen empiirisiset kertymäfunktiot, Kööpenhaminan punaisella. Nähdään, että jakaumat ovat melko lähellä toisiaan. Oikeanpuoleisessa kuviossa on Helsingin tuottojen empiirinen kertymäfunktio. Sen molemmin puolin on merkitty pisteittäinen luottamusvyö vihreällä ja samanaikainen luottamusvyö punaisella.
Testataan vielä, onko Helsingin ja Kööpenhaminan tuottojakaumilla eroa.
ks.test(tuototH, tuototC)
## Warning in ks.test.default(tuototH, tuototC): p-value will be approximate in
## the presence of ties
##
## Asymptotic two-sample Kolmogorov-Smirnov test
##
## data: tuototH and tuototC
## D = 0.071205, p-value = 0.5992
## alternative hypothesis: two-sided
# Nollahypoteesi on, että eroa ei ole, ja se jää voimaan.6.5 Yhteysmitat
Kahden tilastomuuttujan välistä yhteyttä mitataan ns. yhteysmitoilla. Tunnetuin näistä mitoista on Pearsonin korrelaatiokerroin, joka mittaa kahden muuttujan välistä lineaarista riippuvuutta. Tämä korrelaatiokerroin voidaan laskea välimatka-asteikollisille muuttujille. Seuraavassa esitellään yhteysmittoja, jotka eivät mittaa pelkästään lineaarista riippuvuutta. Tosin kaikenlaista riippuvuutta nämäkään mitat eivät paljasta. Ne rajoittuvat tilanteisiin, joissa muuttujien välistä yhteyttä kuvaa monotoninen (kasvava tai vähenevä) käyrä. Yhteys on positiivinen, jos toisen muuttujan kasvaessa toinenkin kasvaa, ja negatiivinen, jos toisen muuttujan kasvaessa toinen vähenee.
Yhteysmitat on standardoitu saamaan arvoja väliltä [-1, 1] ja 0-arvo vastaa muuttujien välistä riippumattomuutta. Mitoille on määritetty sekä pienen otoskoon tarkkoja jakaumia että suuren otoskoon likimääräisiä jakaumia tilanteeseen, jossa muuttujat ovat riippumattomia. Näiden jakaumien avulla voidaan testata riippumattomuutta. Tässäkin on huomattava se, että vaikka nollahypoteesia riippumattomuudesta ei hylättäisi, se ei tarkoita sitä, että muuttujat ovat riippumattomia, sillä mitat eivät reagoi kaikenlaiseen riippuvuuteen.
Satunnaismuuttujat \(X\) ja \(Y\) ovat riippumattomia, jos
\[
F_{XY}(x,y) = F_X(x)F_Y(y),\quad\mbox{kaikilla } x \mbox{ ja } y,
\]
missä \(F_{XY}(x,y)=P(X\le x, Y\le y)\) on muuttujien \(X\) ja \(Y\) yhteisjakauman kertymäfunktio, \(F_X(x)\) satunnaismuuttujan \(X\) kertymäfunktio ja \(F_Y(x)\) satunnaismuuttujan \(Y\) kertymäfunktio.
6.5.1 Spearmanin järjestyskorrelaatiokerroin
Spearmanin järjestyskorrelaatiokerroin voidaan laskea korvaamalla alkuperäiset havainnot niiden sijaluvuilla (eli järjestysluvuilla). Pienin havainto saa sijaluvun 1 ja suurin sijaluvun \(n\), missä \(n\) on havaintoparien lukumäärä. Muuttujien \(x\) ja \(y\) välinen järjestyskorrelaatiokerroin on siis \[ r_S = \frac{\sum_{i=1}^n (R_i-\bar R)(S_i-\bar S)}{\sqrt{\sum_{i=1}^n(R_i-\bar R)^2\sum_{i=1}^n(S_i-\bar S)^2}}, \] missä \(R_i=R(x_i)\) on havainnon \(x_i\) ja \(S_i=S(y_i)\) havainnon \(y_i\) sijaluku, ja \(\bar R\) ja \(\bar S\) ovat näiden sijalukujen keskiarvot. Jos aineistossa on tasahavaintoja, ne korvataan ns. keskisijaluvulla eli kyseisten tasahavaintojen sijalukujen keskiarvolla.
Järjestyskorrelaatiokertoimen etu verrattuna tavalliseen korrelaatiokertoimeen on sen vakaus eli se, ettei se ole herkkä vierashavainnoille. Jos esim. yksittäinen havaintoarvo on “pielessä” se pääsee vaikuttamaan lopputulokseen vain yhden sijaluvun verran. Toinen etu on se, että se voidaan laskea myös järjestysasteikollisille muuttujille. Toisaalta jos muuttujat ovat välimatka-asteikollisia, se hävittää informaatiota, jos tutkitaan nimenomaan lineaarista riippuvuutta.
Kun muuttujat ovat riippumattomia ja otoskoko riittävä, likimain \[ Z = \sqrt{n-1}\cdot r_S \sim N(0,1). \] Käytetään myös t-jakauma-arviota \[ \sqrt{n-2}\frac{r_S}{\sqrt{1-r_S^2}}\sim t(n-2). \]
6.5.2 Kendallin tau
Oletetaan, että havaintoaineistossa on havaintoparit \((x_i,y_j),\ i=1,...,n\) ja määritellään, että havaintoparit \((x_i,y_i)\) ja \((x_j,y_j)\) ovat yhdenmukaisia (concordant), jos erotukset \(x_i-x_j\) ja \(y_i-y_j\) ovat samanmerkkisiä ja epäyhdenmukaisia (disconcordant), jos nämä erotukset ovat erimerkkisiä. Jos aineistossa on paljon yhdenmukaisia havaintoparien pareja, se viittaa siihen, että muuttujilla on positiivinen yhteys, ja päin vastoin. Kendallin otosjärjestyskorrelaatiokerroin \(\tau\) on \[ \tau=\frac{K-D}{n(n-1)/2}, \] missä \(K\) on yhdenmukaisten ja \(D\) epäyhdenmukaisten havaintoparien parien lukumäärä.
Koska havaintoparien muodostamia pareja on kaikestaan \(n(n-1)/2\), Kendallin \(\tau\) on normeerattu välille \([-1, 1]\). Jos aineistossa on tasahavaintoja jommassa kummassa muuttujassa, jolloin \(x_i-x_j=0\) tai \(y_i-y_j=0\) joillakin indeksin arvoilla \(i\) ja \(j\), niin \(K+D < n(n-1)/2\) eikä Kendallin \(\tau\) voi saavuttaa arvoja -1 tai 1.
Voidaan osoittaa, että riippumattomuuden vallitessa ja kun aineistossa ei ole tasahavaintoja, \(\mathrm{E}(K-D)=0\) ja \(\mathrm{Var}(K-D)=n(n-1)(2n+5)/18\). Lisäksi \[ \frac{K-D}{\sqrt{n(n-1)(2n+5)/18}} \] noudattaa likimain standardinormaalijakaumaa riittävällä otoskoolla, mitä voidaan käyttää riippumattomuuden testaamisessa. Jos aineistossa on tasa-havaintoja, varianssin lauseketta täytyy muokata.
6.5.3 Goodmanin ja Kruskalin gamma
Goodmanin ja Kruskalin \(\gamma\) on Kendallin \(\tau\):n tapainen yhteysmitta. Se määritellään kaavalla \[ \gamma = \frac{K-D}{K+D}. \] Se voi saada myös arvon -1 tai 1 vaikka aineistossa olisikin tasa-arvoja. Jos tasa-arvoja ei ole, niin \(\gamma = \tau\) ja \(K+D=n(n-1)/2\).