Luku 4 Regressioanalyysin erityiskysymyksiä
4.1 Mallinvalinta
Usein tutkijalla on selkeä käsitys siitä, mitä selittäjiä hän haluaa sisällyttää malliinsa. Lisäksi jos havaintoaineisto on pieni ja siinä vähän muuttujia, on mahdollista luovasti kokeilla erilaisia selittäjien yhdistelmiä sekä niiden muunnoksia ja yhteisvaikutuksia. Jos kuitenkin tutkijalla ei ole selkeää kuvaa siitä, mitkä tekijät voisivat selittää tulosmuuttujan arvoja ja mahdollisia selittäjiä on paljon, tarvitaan systemaattisempaa lähestymistapaa.
Se mikä lähestymistapa on paras, riippuu mallinnuksen tavoitteista. Tavoitteena voi olla esimerkiksi lineaaristen yhteyksien löytäminen, kausaalisten vaikutussuhteiden selvittäminen tai ennustaminen. Jos tavoitteena on puhtaasti parhaan ennustemallin löytäminen, yksi helppo ja tehokas vaihtoehto on hakea automaattisesti malli, joka minimoi sopivan informaatiokriteerin, esim. Akaiken informaatiokriteerin, arvon. Seuraavassa esittelemme kuitenkin tilastolliseen testaamiseen perustuvan menetelmän.
Poistovalinnassa sovitetaan ensin laaja ja kattava malli, jossa on paljon selittäjiä. Sen jälkeen mallista poistetaan selittäjiä yksi kerrallaan valitsemalla poistettavaksi aina vähiten merkitsevä selittäjä, jolla on suurin p-arvo. Näin jatketaan, kunnes kaikkien jäljelle jääneiden selittäjien p-arvo alittaa edeltä asetetun rajan.
Menetelmän etuna on, että se on selkeä ja yksinkertainen. Lisäksi tutkija voi käyttää omaa harkintaansa ja jättää malliin selittäjiä, jotka siihen hänen mielestään kuuluvat, vaikka ne käytettävällä aineistolla olisikaan merkitseviä. Haittapuolena menetelmässä on, että mukaan saattaa tulla näennäisiä selittäjiä, jotka ovat merkitseviä vain “sattumalta”. Selittäjien todellinen merkitsevyys on pienempi, kuin rajana käytettävästä p-arvosta voisi päätellä. Lisäksi menetelmä ei ole optimaalinen ennustemallin rakentamisessa.
Esim. Tarkastellaan R-aineistoa mtcars, joka sisältää polttoaineen kulutuksen sekä 10 rakennetta ja suorituskykyä kuvaavaa muuttujaa 32 henkilöautolta (mallit 1973–74). Aineisto on poimittu Yhdysvaltain vuoden 1974 Motor Trend -lehdestä.
Aineistossa on seuraavat muuttujat:
| nimi | selitys |
|---|---|
| mpg | Miles/(US) gallon |
| cyl | Number of cylinders |
| disp | Displacement (cu.in.) |
| hp | Gross horsepower |
| drat | Rear axle ratio |
| wt | Weight (1000 lbs) |
| qsec | 1/4 mile time |
| vs | Engine (0 = V-shaped, 1 = straight) |
| am | Transmission (0 = automatic, 1 = manual) |
| gear | Number of forward gears |
| carb | Number of carburetors |
Tarkastellaan aluksi mallia, jossa kaikki selittäjät ovat mukana.
summary(lm(mpg ~ ., data = mtcars))
##
## Call:
## lm(formula = mpg ~ ., data = mtcars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.4506 -1.6044 -0.1196 1.2193 4.6271
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 12.30337 18.71788 0.657 0.5181
## cyl -0.11144 1.04502 -0.107 0.9161
## disp 0.01334 0.01786 0.747 0.4635
## hp -0.02148 0.02177 -0.987 0.3350
## drat 0.78711 1.63537 0.481 0.6353
## wt -3.71530 1.89441 -1.961 0.0633 .
## qsec 0.82104 0.73084 1.123 0.2739
## vs 0.31776 2.10451 0.151 0.8814
## am 2.52023 2.05665 1.225 0.2340
## gear 0.65541 1.49326 0.439 0.6652
## carb -0.19942 0.82875 -0.241 0.8122
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.65 on 21 degrees of freedom
## Multiple R-squared: 0.869, Adjusted R-squared: 0.8066
## F-statistic: 13.93 on 10 and 21 DF, p-value: 3.793e-07Näemme, ettei yksikään selittäjä ole merkitsevä 5 % riskitasolla. Ongelmana on multikollineaarisuus; selittäjillä on vahvoja lineaarisia riippuvuuksia. Pudotetaan pois selittäjä cyl, joka on vähiten merkitsevä (p=0.961)
summary(lm(mpg ~ . - cyl, data = mtcars))
##
## Call:
## lm(formula = mpg ~ . - cyl, data = mtcars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.4286 -1.5908 -0.0412 1.2120 4.5961
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 10.96007 13.53030 0.810 0.4266
## disp 0.01283 0.01682 0.763 0.4538
## hp -0.02191 0.02091 -1.048 0.3062
## drat 0.83520 1.53625 0.544 0.5921
## wt -3.69251 1.83954 -2.007 0.0572 .
## qsec 0.84244 0.68678 1.227 0.2329
## vs 0.38975 1.94800 0.200 0.8433
## am 2.57743 1.94035 1.328 0.1977
## gear 0.71155 1.36562 0.521 0.6075
## carb -0.21958 0.78856 -0.278 0.7833
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.59 on 22 degrees of freedom
## Multiple R-squared: 0.8689, Adjusted R-squared: 0.8153
## F-statistic: 16.21 on 9 and 22 DF, p-value: 9.031e-08Tilanne ei ole paljon muuttunut; selittäjän wt p-arvo on hiukan pienentynyt. Jatkamalla tätä prosessia päädytään malliin, jossa on kolme merkitsevää selittäjää.
summary(lm(mpg ~ wt + qsec + am, data = mtcars))
##
## Call:
## lm(formula = mpg ~ wt + qsec + am, data = mtcars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.4811 -1.5555 -0.7257 1.4110 4.6610
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 9.6178 6.9596 1.382 0.177915
## wt -3.9165 0.7112 -5.507 6.95e-06 ***
## qsec 1.2259 0.2887 4.247 0.000216 ***
## am 2.9358 1.4109 2.081 0.046716 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.459 on 28 degrees of freedom
## Multiple R-squared: 0.8497, Adjusted R-squared: 0.8336
## F-statistic: 52.75 on 3 and 28 DF, p-value: 1.21e-11Tällainen yksinkertainen malli on helppo tulkita. On luonnollista, että painavampi auto kuluttaa enemmän. Näemme myös, että hitaammin kiihtyvä, manuaalivaihteinen auto kulutti vähemmän.
Selitysaste on pienentynyt alkuperäisen mallin luvusta 0.869 lukuun 0.8497. Selitysaste on huono mittari mallinvalinnassa, koska se kasvaa aina, kun malliin lisätään selittäjiä. Se tavallaan ylipalkitsee mallin sopivuudesta niin, että mallin systemaattinen osa pyrkii sovittamaan satunnaisvaihteluakin. Sen sijaan muokattu selitysaste (Adjusted R-squared), joka käyttää harhatonta estimaattia virhetermin varianssille, on parempi. Se määritellään \[ R^2_{adj}=1-\frac{\mathrm{JNS}/(n-k-1)}{\mathrm{KNS}/(n-1)}. \] Näemme, että muokattu selitysaste on parempi valitussa suppeassa mallissa (0.8336) kuin alkuperäisessä mallissa (0.8066).
4.2 Muuttujien logaritmointi
Erilaiset muunnokset regressiomallin selittäjille tai selitettävälle voivat parantaa mallin ja havaintoaineiston yhteensopivuutta. Muunnosten seurauksena tulosten tulkinta saattaa kuitenkin vaikeutua. Logaritmimuunnos, joka lienee yleisimmin käytetty muunnos, kuitenkin säilyttää tulkittavuuden. Tulkinta on tosin erilainen kuin käytettäessä alkuperäistä muuttujaa. Jos regressiokerroin on riittävän pieni, voidaan myös käyttää arviota, joka helpottaa tulkintaa.
Arvio perustuu siihen, että \[ \log(1+\delta)\approx \delta, \] kun \(\delta\approx 0\). Tätä havainnollistaa seuraava kuvio, jossa funktiota \(y=\log(1+x)\) sivuaa suora \(y=x\). Vastaava approksimaatio eksponenttifunktiolle on \[ \exp(\delta)\approx 1+\delta. \]
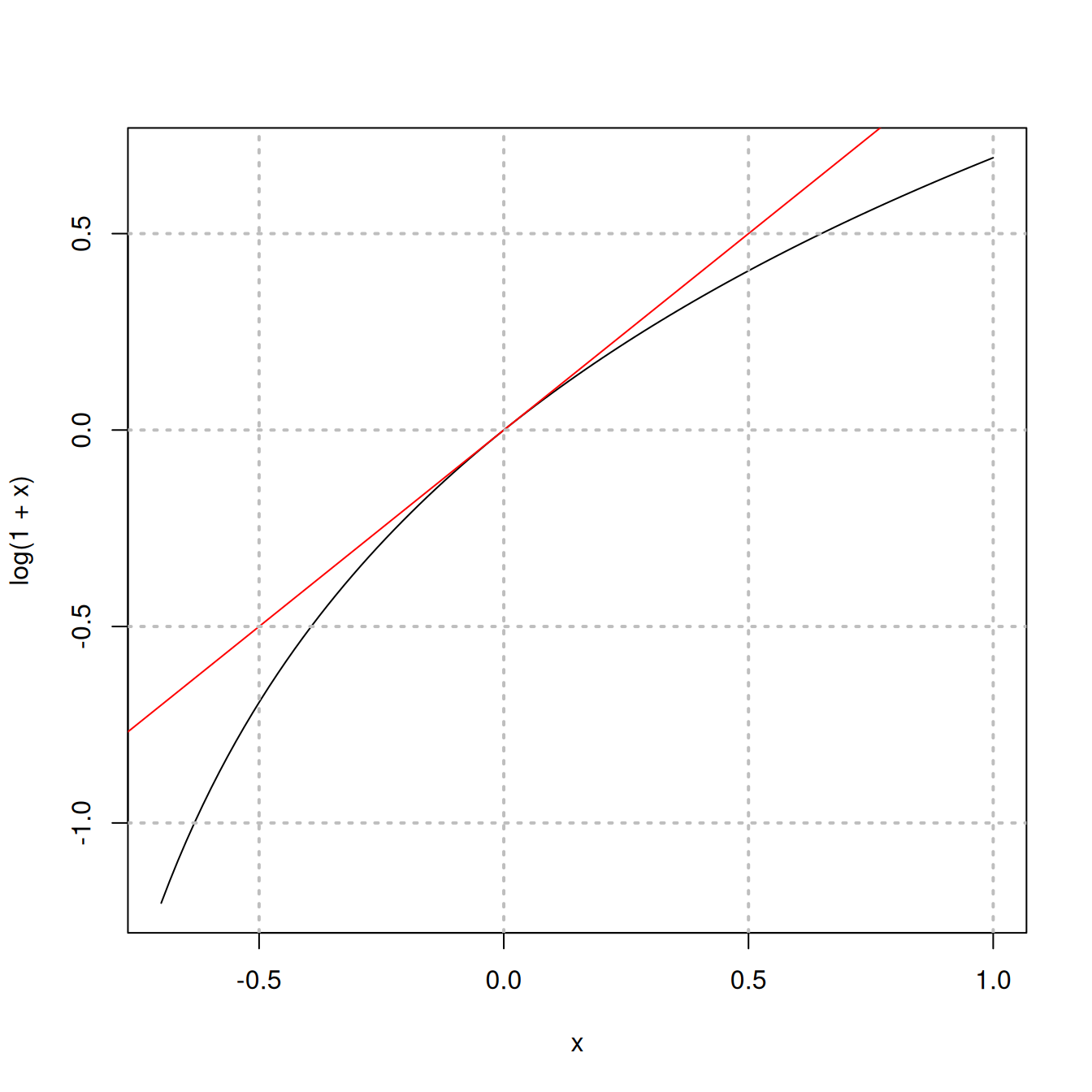
Tarkastellaan seuraavassa yksinkertaisuuden vuoksi yhden selittäjän mallia. Tulkinnan kannalta esiintyy kolme tapausta:
Selittäjä on logaritmoitu. Malli on muotoa \[ Y=\beta_0 +\beta_1 \log(x)+\epsilon. \] Kun selittäjä \(x\) kasvaa \((1+\delta)\)-kertaiseksi eli \(100\cdot\delta\ \%\), selitettävä kasvaa luvulla \[\begin{eqnarray*} &&\left[\beta_0 +\beta_1 \log((1+\delta) x)+\epsilon\right]-\left[\beta_0 +\beta_1 \log(x)+\epsilon\right]\\ =&& \beta_1 \log(1+\delta)\approx \beta_1\delta. \end{eqnarray*}\] Likiarvo on yleensä riittävän tarkka, kun \(|\delta| < 0.1\). Tällöin arvio heittää vähemmän kuin yhdellä sadasosalla (0.01).
Selitettävä on logaritmoitu. Malli on muotoa \[ \log(Y)=\beta_0 +\beta_1 x + \epsilon. \] Kun selittäjä \(x\) kasvaa luvulla \(\delta\), yhtälön molempiin puoliin lisätään \(\beta_1\delta\) ja \(\log(Y)\) kasvaa lukuun \[ \beta_1 \delta+ \log(Y) = \log(e^{\beta_1\delta}Y)\approx\log[(1+\beta_1\delta)Y], \] eli selitettävä \(Y\) kasvaa \(\exp(\beta_1\delta)\)-kertaiseksi. Kasvu on siis noin \(100\cdot\beta_1\delta\ \%\), kun \(|\beta_1\delta|\) on pieni (<0.1).
Sekä selitettävä että selitettävä on logaritmoitu. Malli on muotoa \[ \log(Y)=\beta_0 +\beta_1\log(x)+\epsilon, \] tai \[ Y=e^{\beta_0}x^{\beta_1}e^{\epsilon}. \] Kun \(x\) kerrotaan luvulla \((1+\delta)\), \(Y\) kasvaa lukuun \[ e^{\beta_0}[(1+\delta)x]^{\beta_1}e^{\epsilon}=(1+\delta)^{\beta_1}e^{\beta_0}x^{\beta_1}e^{\epsilon}, \] eli se tulee kerrotuksi luvulla \((1+\delta)^{\beta_1}\approx 1+\beta_1\delta\). Siis jos \(x\) kasvaa \(100\cdot\delta\ \%\), \(Y\) kasvaa noin \(100\cdot\beta_1\delta\ \%\). Arvio on jälleen tarkka, mikäli \(|\beta_1\delta|\) on riittävän pieni (<0.1).